Корпуси
Български национален корпус (БНК)
"Brown" корпус за български език
"Brown" корпус за български език с целите текстове
Български POS анотиран корпус (БулПосКор)
Български семантично анотиран корпус (БулСемКор)
Българско-английски паралелен корпус със съотнесени изречения и клаузи (BulEnAC)
Wiki1000+ - анотиран корпус със съставни лексикални единици
Български национален корпус (БНК)
![]()
Общо описание: Българският национален корпус е създаден в Института за български език „Проф. Любомир Андрейчин” от сътрудници от Секцията по компютърна лингвистика и Секцията за българска лексикология и лексикография. В него са обединени няколко отделни електронни корпуса, разработени в периода 2001-2009 г. за целите на двете секции. Материалите в корпуса отразяват състоянието на българския език (предимно в неговата писмена форма) от средата на ХХ в. (1945 г.) до наши дни.
Нарастването на БНК се извършва не само чрез събирането на текстове на български език, но и чрез включването на паралелни корпуси, в които централният език е български. Това означава, че текстовете на чужди езици задължително имат съответствие на български, което се включва в ядрото на корпуса, съдържащо всички текстове на български език, включени в него.
Към края на януари 2013 ядрото на корпуса съдържа приблизително 1,2 милиарда думи и над 240 000 текста. В момента са включени паралелни корпуси на 47 езика с обем около 4,2 милиард думи. Общият обем на БНК е приблизително 5,4 милиарда думи.
Корпусът включва три нива на анотация:
• подробни метаданни, включващи информация за автор, дата на създаване, дата на публикуване, тип, жанр, област и др.;
• едноезикова анотация – токънизация и разделяне на изречения; автоматично приписване на частта на речта, на граматичните характеристики и основната форма на думите; автоматично приписване на значенията на думите от Българския WordNet;
• многоезикова анотация – съотнасяне на различни езикови нива, за момента – съотнасяне по изречения и по клаузи (прости изречения в състава на сложното) за част от корпуса.
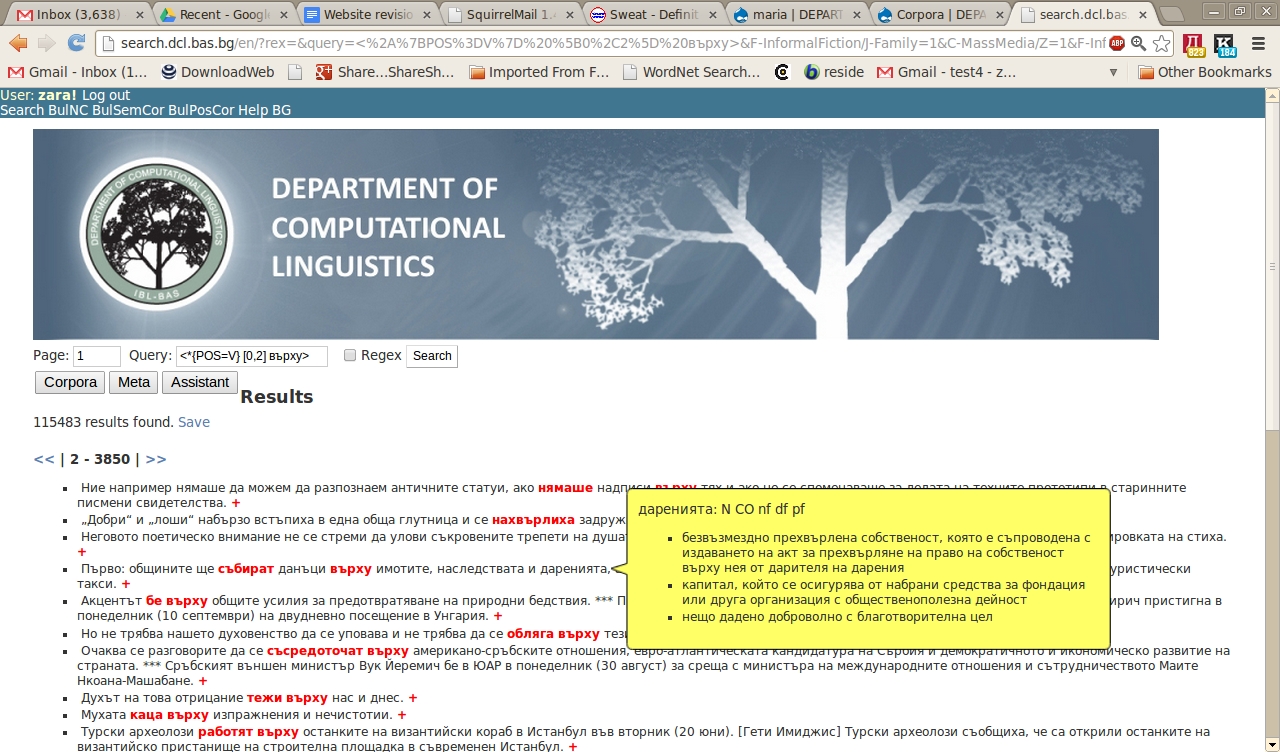
Създадена е специална система за търсене в корпуса, която дава възможност за комплексни заявки по различни езикови критерии.
Тагсетът, използван при анотацията на Българския национален корпус, е достъпен оттук.
Езици: общо 48 езика: български и 47 чужди езика (включени в паралелните корпуси)
Тип: общ многоезиков корпус от писмена и устна реч, включващ множество специализирани подкорпуси; снабден с подробни метаданни и многослойна лингвистична анотация
Съдържание: над 240,000 текста, разпределени в 9 категории; общ обем: около 5,4 милиарда думи
Приложения: Българският национален корпус дава възможност за редица приложения в различни области на езикознанието: в компютърната лингвистика; в лексикографията; за теоретични изследвания на определени лингвистични явления; за наблюдения върху особеностите на отделни области на езика; за извличане на примери за демонстрация при обучението по български език и др.
Анотация: едноезикова анотация: токънизация и разделяне на изречения; автоматично приписване на частта на речта, на граматичните характеристики и основната форма на думите; автоматично приписване на значенията на думите от Българския WordNet; многоезикова анотация: съотнасяне по изречения и клаузи на част от корпуса; подробни метаданни;
Условия за достъп: Свободен достъп чрез интернет чрез системата за търсене на Българския национален корпус:
• свободно търсене онлайн, ограничено до 30 случайни резултата (за нерегистрирани потребители);
• пълен достъп до резултатите (за регистрирани потребители);
• свободно изтегляне на незащитените с авторско право текстове (за регистрирани потребители).
URL: Уебстраница на БНК: http://dcl.bas.bg/bulnc/, Система за търсене в БНК: http://search.dcl.bas.bg/
За безплатно изтегляне на свободно достъпните подкорпуси и на честотните речници, извлечени от БНК: http://dcl.bas.bg/BulNC/.
![]()
Общо описание: В последните години в Секцията по компютърна лингвистика са създадени 47 паралелни корпуса, фокусирани върху българския език, с различна големина и разнообразие в зависимост от наличието на паралелни текстове за съответната двойка езици. Измежду паралелните корпуси са: английски, немски, френски, славянските и балканските езици, както и други европейски и неевропейски (както езиково, така и географски) езици.
Паралелните корпуси включват само текстове, които имат българско съответствие – оригиналът е на български или има български превод на съответния текст, или двата текста са превод от трети език.
Паралелните корпуси са включени в Българския национален корпус (БНК), като структурата, форматът на данните и описанието им следват модела на БНК. Текстовете са снабдени с подробни метаданни, извлечени автоматично, където е възможно, и при необходимост разширени ръчно.
Корпусите се допълват постоянно с нови текстове, за да се осигури разнообразие от стилове, тематични области и жанрове. В момента (към края на януари 2013) общият им обем е почти 4,2 милиарда думи.
Езици: 47 паралелни българско-X-езикови корпуса (общо 48 езика: български и 47 чужди езика)
Тип: многоезиков паралелен корпус от писмена и устна реч
Съдържание: Отделните корпуси имат различен обем; общ обем: 1 789 872 текста; почти 4,2 милиарда думи
Приложения: Основните приложения на паралелните корпуси са в областта на компютърната лингвистика – автоматичен превод, изработване на двуезични лексикални ресурси (речници) и други.
Анотация: токънизация и разделяне на изречения (за всички корпуси); автоматично приписване на правилната част на речта, граматични характеристики и основна форма (за Българо-английския паралелен корпус)
Условия за достъп: Свободен достъп чрез интернет чрез системата за търсене на Българския национален корпус: http://search.dcl.bas.bg/bg/:
• свободно търсене онлайн, ограничено до 30 случайни резултата (за нерегистрирани потребители);
• пълен достъп до резултатите (за регистрирани потребители);
• свободно изтегляне на незащитените с авторско право текстове (за регистрирани потребители).
URL: Уебстраница на Бул-X-Кор:
http://www.ibl.bas.bg/BGNC_parallel_bg.htm
"Brown" корпус за български език
![]()
Общо описание: Структурираният корпус на българския език, или "Brown" корпус за български език е създаден в съответствие с методологията, разработена в университета Браун (Brown university, Providence, Rhode Island, USA) и приложена в създаването на известния Brown Corpus of Standard American.
"Brown" корпусът за български език включва 500 текста, разпределени в 15 категории от 2 типа текстове - художествени и информативни. Дължината на текстовете е от 2 000+ думи, като точният им брой варира, тъй като методологията предвижда запазване на границите на изреченията. Големината на корпуса е над 1 001 286 думи.
Корпусните единици са части от текстове, създадени или публикувани като първо издание в периода 1990-2005, основната част - след 2000 година.
Корпусът е документиран, направени са проверки за погрешна замяна на кирилски с латински букви и за правописни и пунктуационни грешки.
Съществуват две версии на корпуса. Първата е създадена през 2001-2002 година. При съставянето са пренебрегнати някои принципи на Brown Corpus of Standard American English (текстовете да са оригинални, да са съвременни и др.) поради невъзможност да се покрият всички категории. Опитът от създаването на първата версия, както и значителното нарастване на електронните публикации в периода 2002-2005 г. дават възможности за съставянето на втората версия на корпуса.
Корпусът е включен в структурата на Българския национален корпус (БНК).
Език: български
Тип: общ едноезиков корпус от писмена реч, снабден с лингвистична анотация
Съдържание: 500 текста от по 2000+ думи, разделени в 15 категории от 2 типа – художествени и информативни; общ обем: 1 001 286 думи свързан текст
Приложения: Едно от главните приложения на корпуса е при извличането на структурирани подкорпуси за създаването на анотирани корпуси като БулПосКор и БулСемКор. Позволява създаването на честотни списъци, статистика за употребата, списъци с обща лексика и друга информация. Използван е при теоретичната обосновка за създаване на общи и специализирани корпуси, за усъвършенстване на методологиите за създаване на корпуси, за изработването на единна класификация за структуриране на корпуси и др.
Анотация: токънизация и разделяне на изречения, автоматично определяне на частта на речта, на граматичните характеристики и на основната форма
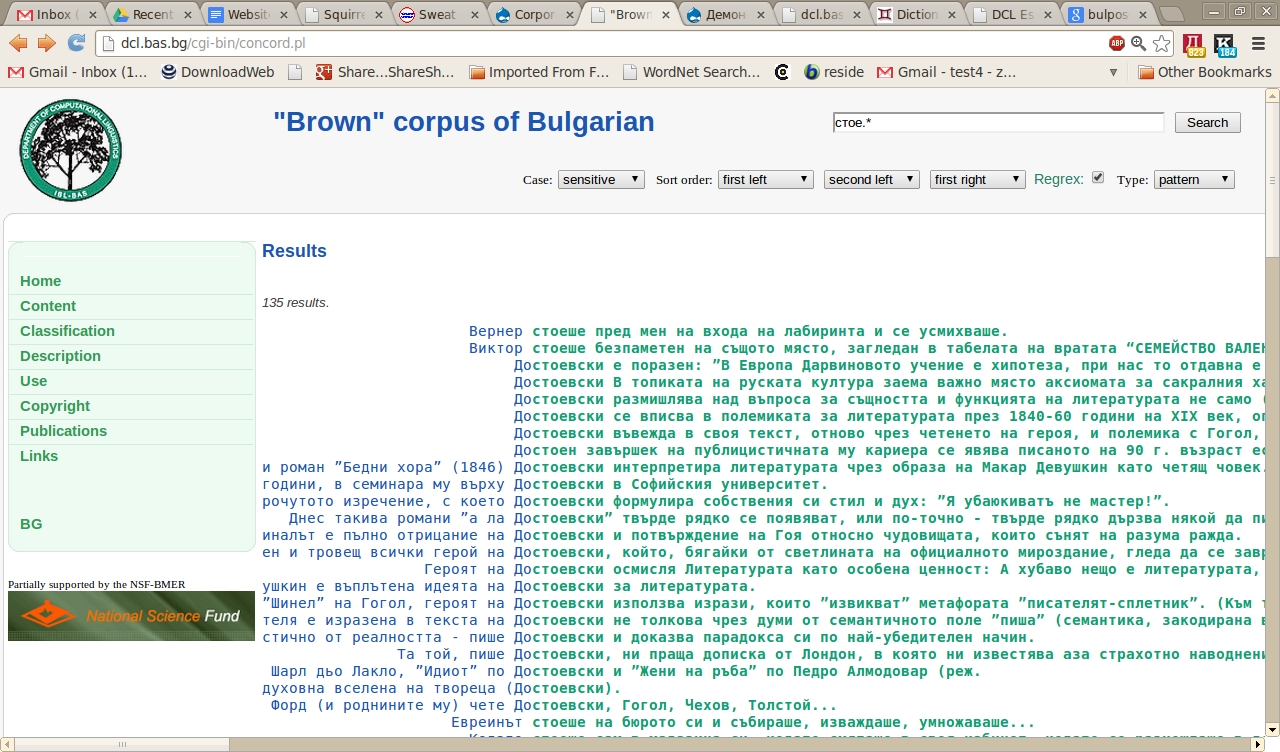
Условия за достъп: Свободен достъп чрез интернет чрез собствена система за търсене: http://www.ibl.bas.bg/Corpus/home_bg.html;
свободен достъп чрез интернет чрез системата за търсене на Българския национален корпус: http://search.dcl.bas.bg/bg/:
• свободно търсене онлайн, ограничено до 30 случайни резултата (за нерегистрирани потребители);
• пълен достъп до резултатите (за регистрирани потребители);
• свободно изтегляне на незащитените с авторско право текстове (за регистрирани потребители).
"Brown" корпус за български език с целите текстове
![]()
Общо описание: "Brown" корпусът за български език с целите текстове представлява структуриран общ корпус от текстове на съвременен български език, публикувани в електронен вид в интернет в периода 1990-2005 година, създаден според методологията и класификацията на Brown Corpus of Standard American English, адаптирани за конкретните цели. Корпусът съдържа пълния обем на текстовете, включени във втората версия на "Brown" корпуса за български език, и има общ обем 4 799 304 думи.
Корпусът е включен в Българския национален корпус (БНК).
Език: български
Тип: писмен, едноезиков, общ корпус с лингвистична анотация
Съдържание: 500 текста, разделени в 15 категории от 2 типа – художествени и информативни. Корпусът съдържа общо 4 799 304 думи свързан текст
Приложения: Корпусът се използва за сравнителен анализ с "Браун" корпуса на български език. Позволява създаването на честотни списъци, статистика за употребата, списъци с обща лексика и друга информация. Използван е при теоретичната обосновка за създаване на общи и специализирани корпуси, за усъвършенстване на методологиите за създаване на корпуси, за изработването на единна класификация за структуриране на корпуси и др.
Анотация: токънизация и разделяне на изречения, автоматично определяне на частта на речта, на граматичните характеристики и на основната форма
Условия за достъп: Свободен достъп чрез интернет чрез системата за търсене на Българския национален корпус: http://search.dcl.bas.bg/bg/:
• свободно търсене онлайн, ограничено до 30 случайни резултата (за нерегистрирани потребители);
• пълен достъп до резултатите (за регистрирани потребители);
• свободно изтегляне на незащитените с авторско право текстове (за регистрирани потребители).
при заявка: безплатно предоставяне на статистики върху корпуса, честотни списъци на словоформи, леми и др.; за контакт: dcl@dcl.bas.bg
Български POS анотиран корпус (БулПосКор)
![]()
Общо описание: Тагираният корпус за български език е конструиран от Структурирания "Brown" корпус за българския език и е с големина 174 697 лексикални единици. Структурата на "Brown" корпуса е запазена – от всеки текст в него е направена извадка от минимум 300 думи, като извадките са разширени до край на изречение.
Граматическите характеристики на всяка словоформа са определени коректно и еднозначно от лингвисти с помощта на системата за анотиране на текстове Chooser.
Части от тагирания корпус са използвани като тренировъчни или тестови корпуси при създаването на програми за автоматично отстраняване на граматична многозначност (тагери), какъвто е BgTagger. Тагираният корпус предлага възможности за ефективно търсене на езикови модели и форми в текста.
Език: български
Тип: общ едноезиков корпус от писмена реч, снабден с лингвистична анотация
Съдържание: текстове от по 300+ думи, разделени в 15 категории от 2 типа – художествени и информативни; общ обем: 174 697 лексикални единици
Приложения: Отстраняването на многозначността на всички равнища на езика е необходимо за създаването на различни видове програмни приложения за обработване на естествен език, както и за целите на теоретичните и теоретично-приложните лингвистични изследвания.
Анотация: токънизация и разделяне на изречения; определяне на частта на речта, на граматичните характеристики и на основната форма на всички думи в корпуса, извършено от експерти лингвисти
Условия за достъп:Свободен достъп чрез интернет чрез системата за търсене на Българския национален корпус:
• свободно търсене онлайн.
URL: http://dcl.bas.bg/poscor/bg/
Български семантично анотиран корпус (БулСемКор)
![]()
Българският семантично анотиран корпус се състои от 811 откъса от по 100+ думи (при запазване на границите на изреченията), извлечени от Структурирания "Brown" корпус за български език. Подборът на текстовете следва определена методология, за да се обхванат концентрациите с най-често срещаните думи от отворените класове. В резултат изходният корпус за семантична анотация е с обем от 101 062 токъна.
Думите в корпуса са лематизирани и са свързани с възможното множество от значения в Българския WordNet, асоциирани със съответната лема. На всяка една единица (дума или съставна дума) в БулСемКор е приписано уникалното семантично или граматично значение, което се реализира в даден контекст. Анотираният корпус съдържа общо 99 480 лексикални единици.
Семантичната анотация е извършена със специално създадена програма за лингвистична анотация Chooser.
Семантичният корпус e използван като тренировъчен и тестов корпус при създаването на вероятностен формализъм и на програма за автоматично отстраняване на семантичната многозначност (BGWSD) за целите на автоматичния превод.
Език: български
Тип: общ едноезиков корпус от писмена реч, снабден с лингвистична анотация
Съдържание: 811 текста от по 100+ думи, разделени в 15 категории от 2 типа – художествени и информативни; общ обем: изходен корпус – 101 062 токъна, анотиран корпус – 99 480 лексикални единици
Приложения: Части от Българския семантично анотиран корпус са използвани като тренировъчен и тестов корпус при създаването на вероятностен формализъм и на програма за автоматично отстраняване на семантичната многозначност.
Анотация: токънизация и разделяне на изречения; определяне на частта на речта и на основната форма на думите в корпуса; еднозначно определяне на значението на всички думи от корпуса в съответния контекст, извършено от експерти лингвисти
Условия за достъп:
Свободен достъп чрез интернет чрез системата за търсене на Българския национален корпус:
• свободно търсене онлайн.
URL: http://dcl.bas.bg/semcor/bg/.
Българско-английски паралелен корпус със съотнесени изречения и клаузи (BulEnAC)
![]()
Общо описание: Българско-английският паралелен корпус със съотнесени изречения и клаузи (BulEnAC) е извадка от Българско-английския паралелен корпус, който е част от Българския национален корпус (БНК).
BulEnAC включва 176 397 токъна в българския подкорпус и 190 468 токъна в английския подкорпус (общо 366 865 токъна). Текстовете са разделени в следните категории: Административни текстове (20,5%), Художествена литература (21,35%), Публицистика (37,13%), Научни текстове (11,16%) и Разговорни/Художествени текстове (9,84%).
Българската и английската част на корпуса са автоматично разделени и съотнесени на ниво изречение. Българските сложни изречения са ръчно разделени на прости изречения. За определяне на границите на простите изречения в състава на сложното в английския подкорпус е използван предварително трениран OpenNLP парсер, след което резултатите са проверени и коригирани от експерти. Паралелните клаузи са ръчно съотнесени в рамките на съответстващите си изречения.
Езици: български и английски
Тип: общ двуезиков паралелен корпус от писмена реч, снабден с лингвистична анотация
Съдържание: общо 366 865 токъна: 176 397 токъна, разпределени в 14 667 изречения за българския подкорпус, 190 468 токъна и 15 718 изречения за английския подкорпус
Анотация: едноезикова анотация - токънизация и разделяне на изречения, автоматично приписване на частта на речта и основната форма; многоезична анотация – съотнасяне на изреченията и клаузите в двата езика
Условия за достъп: при заявка
URL: http://dcl.bas.bg/clauseAlignedCorpus.html
Публикации: Koeva, Svetla, Borislav Rizov, Ekaterina Tarpomanova, Tsvetana Dimitrova, Rositsa Dekova, Ivelina Stoyanova, Svetlozara Leseva, Hristina Kukova, and Angel Genov (2012) "Bulgarian-English Sentence- and Clause-Aligned Corpus" – In: Proceedings of the Second Workshop on Annotation of Corpora for Research in the Humanities (ACRH-2), Lisbon, 29 November 2012., Lisboa: Colibri, 2012, pp. 51-62. ISBN: 978-989-689-273-9. pdf
Wiki1000+ анотиран корпус със съставни лексикални единици
![]()
Общо описание: Корпусът Wiki1000+ е създаден автоматично от Уикипедия и представлява част от Българския национален корпус. Текстовете спадат към научно-популярния стил, като всеки от тях се състои от най-малко 1000 токъна.
Корпусът включва анотация на съставните именни групи, която се базира на следните критерии:
• дали именната група е именувана същност (named entity);
• дали именната група съдържа референция към именувана същност;
• дали значението и е композирано и може да бъде представено като сума от значенията на съставляващите го елементи.
Език: български
Тип: писмен, едноезиков корпус от научно-популярни текстове, извлечени от Уикипедия, снабден с лингвистична анотация
Съдържание: 6311 статии от Уикипедия, всяка от които съдържа поне 1000 токъна, с общ обем 13,4 милиона думи
Анотация: токънизация и разделяне на изречения, автоматично определяне на частта на речта и основната форма; анотация на именни групи
Формат: XML
Условия за достъп: свободен достъп с възможност за изтегляне; корпусът се разпространява с лиценз Creative Commons Attribution-NonCommercial 3.0 Unported License.

URL: http://dcl.bas.bg/wikiCorpus.html