Българско-английски паралелен корпус със съотнесени изречения и клаузи
Общо описание
Българско-английският паралелен корпус със съотнесени изречения и клаузи (BulEnAC) е извадка от Българско-английския паралелен корпус, част от Българския национален корпус (БНК) с обем 260,7 милиона токъна за български и 263,1 милиона токъна за английски.
BulEnAC включва 176 397 токъна в българския подкорпус и 190 468 токъна в английския подкорпус (общо 366 865 токъна). Броят на изреченията в българския подкорпус е 14 667, със средна дължина на изреченията 12,02 думи, а в английския - 15 718, със средна дължина на изреченията 12,11 думи. Средният брой на простите изречения в състава на сложното е 1,67 за български и 1,85 за английски.
Българско-английският паралелен корпус е обработен на няколко нива: токънизация, разделяне на изречения, лематизация. За обработката на българския подкорпус е използвана Българската многокомпонентна система за първична обработка и лингвистична анотация на текстове, а за английската Apache OpenNLP и Stanford CoreNLP (Коева и др. 2012a, Коева и др. 2012b).
Компилация
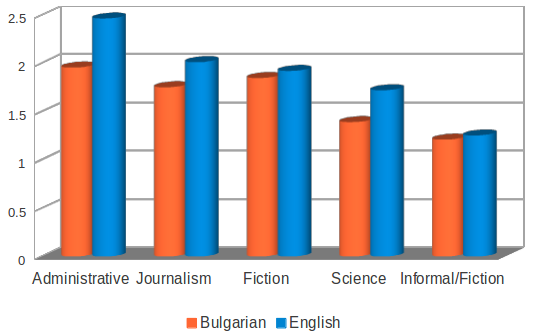
Текстовете са разделени в следните пет категории (стилове): Административни текстове (20,5%), Художествена литература (21,35%), Публицистика (37,13%), Научни текстове (11,16%) и Разговорни/Художествени текстове (9,84%).
Корпусът е представен в плитък XML формат и е снабден с различни нива на едноезикова и многоезикова лингвистична анотация. Едноезиковата анотация и за двата подкорпуса включва разделяне на изречения, токънизация, лематизация, автоматично определяне на частта на речта и на граматичните характеристики. Двуезиковата анотация включва съотнасяне на изреченията и клаузите в българския и в английския подкорпус.
Всяка дума е представена като елемент от тип word. Всеки елемент от този тип се дефинира от множество атрибути, които съответстват на различните нива на анотация:
• лексикално ниво (лематизация) – атрибутите w и l означават съответно словоформа и лема;
• синтактично ниво (изреченско ниво) – комбинацията от два атрибута e=True и sen=senID обозначава края на изречението и съответното id на изречението в корпуса;
• синтактично ниво (ниво на клаузите) – атрибутът cl съответства на идентификатора id на клаузата, в която се появява думата;
• синтактично ниво (само за съюзи) – атрибутът cl2 означава идентификатор id на клаузата, с която дадена съюзна дума свързва синтактично клаузата, чийто конституент е. Атрибутът m обозначава типа на релацията между двете клаузи cl и cl2 (координация или субординация), посоката на релацията (при субординацията) и позицията на съюзната дума по отношение на клаузите, които свързва;
• синтактично ниво (междуезиково съотнасяне) – атрибутите sen_al и cl_al дефинират съотнасянето на ниво изречение и на ниво клаузи, съответно. Съответстващите си изречения/клаузи в два паралелни текста получават един и същи идентификатор id.
Анотация
Съотнасянето на ниво изречения и клаузи от човек, както и проверката и корекцията на автоматичното съотнасяне, са извършени със специално разработена програма – ClauseChooser.
Програмата има два режима на работа – за едноезикова и за паралелна анотация.
Режимът за едноезикова анотация включва следните функции:
• разделяне на изречения;
• разделяне на клаузи;
• корекция на неправилно определени изречения или клаузи (сливане или разделяне на изречения и клаузи);
• анотация на съюзни думи;
• означаване на типа релация между двойки синтактично свързани клаузи.
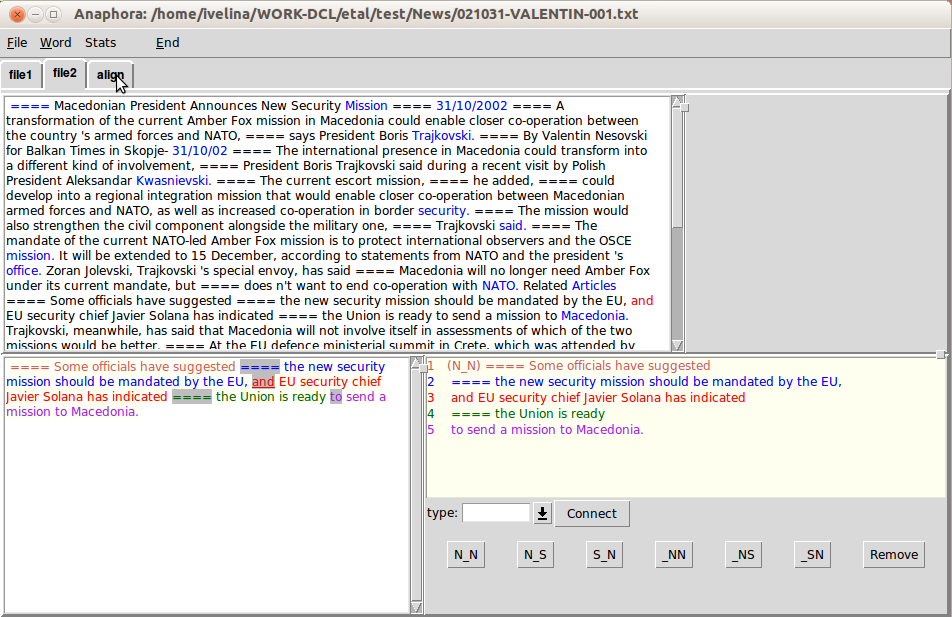
Режимът за паралелна анотация използва резултатът от едноезиковата анотация. Включва следните функции:
• ръчно съотнасяне на изречения;
• ръчно съотнасяне на клаузи.
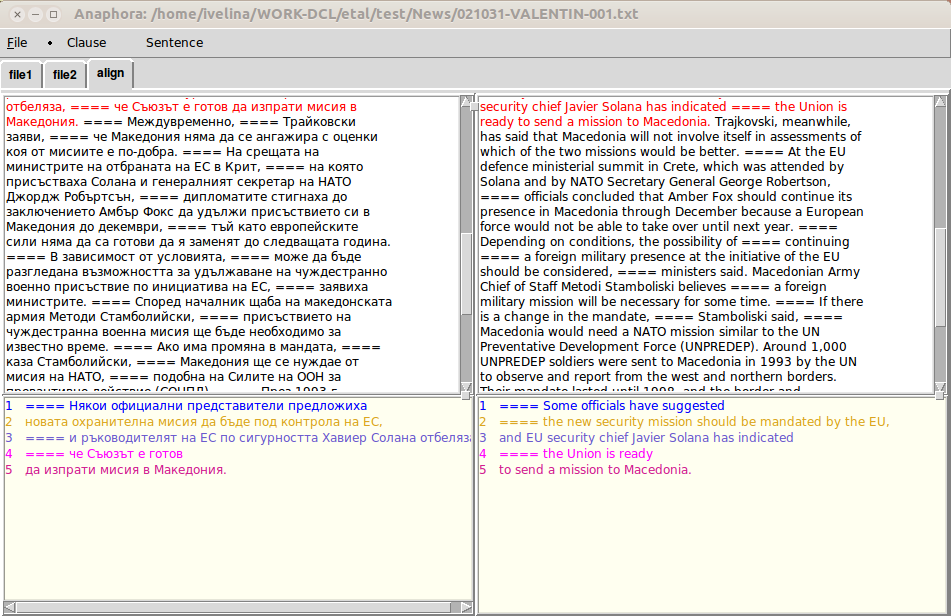
Съотнасяне по изречения и клаузи
Българската и английската част на корпуса са автоматично разделени и съотнесени на ниво изречение. Разделянето на изреченията в българския подкорпус е извършено с помощта на програмата BG Sentence Splitter, която разпознава на границите на изреченията в необработен текст на български език с помощта на правила и речник (Коева и Генов 2011). Разделянето на изреченията в английския подкорпус е извършено с имплементация на предварително трениран модел на OpenNLP. Съотнасянето на изреченията в двата езика е изпълнено автоматично с помощта на HunAlign, с последваща проверка и при необходимост корекция от експерти.
| съотнасяне BG:EN | честота | дял от общия брой в % |
| 0:1 | 1187 | 7.60 |
| 1:0 | 225 | 1.44 |
| 1:1 | 13697 | 87.74 |
| 1:2 | 264 | 1.69 |
| 2:1 | 187 | 1.20 |
| други | 15 | 0.33 |
За определяне на границите на простите изречения в състава на сложното в английския подкорпус е използван предварително трениран OpenNLP парсер, след което резултатите са проверени и коригирани от експерти. Българските сложни изречения са ръчно разделени на прости изречения. При извършване на задачата са взети предвид конкретните синтактични правила, както и установената граматична традиция и анотационни практики за съответните езици, чрез което се цели автентичност на решенията при анотацията и очертаване на езиково специфични проблеми на междуезиковото съотнасяне на езикови единици.
След разделянето и/или проверката на разделените клаузи са идентифицирани съюзните думи, типът релация, която въвеждат, и клаузите, между които е валидна, както и посоката на релацията.
Паралелните клаузи са ръчно съотнесени в рамките на съответстващите си изречения.
| съотнасяне BG:EN | честота | дял от общия брой в % |
| 0:1 | 1745 | 7.05 |
| 1:0 | 482 | 1.95 |
| 1:1 | 18997 | 76.80 |
| 1:2 | 2256 | 9.12 |
| 1:3 | 239 | 1.33 |
| 1:4 | 99 | 0.40 |
| 2:1 | 621 | 2.51 |
| 2:2 | 87 | 0.32 |
| други | 128 | 0.52 |
Приложения
Приложенията на корпуса BulEnAC в областта на обработката на език обхващат поне три взаимосвързани области:
• разработване на методи за автоматично разделяне и съотнасяне по клаузи;
• разработване на методи за промяна на словореда на клаузи с оглед на оптимизиране на тренировъчните данни за статистическия автоматичен превод (SMT) (Коева и др. 2012b);
• съотнасяне на ниво думи и фрази.
Публикации
Коева и др. 2012a: Koeva, Svetla, Borislav Rizov, Ekaterina Tarpomanova, Tsvetana Dimitrova, Rositsa Dekova, Ivelina Stoyanova, Svetlozara Leseva, Hristina Kukova, and Angel Genov (2012a) "Application of Clause Alignment for Statistical Machine Translation". In: Proceedings of SSST-6, Sixth Workshop on Syntax, Semantics and Structure in Statistical Translation, Jeju, Republic of Korea, 12 July 2012, The Association for Computational Linguistics: ACL 2012 / SIGMT / SIGLEX Workshop, 2012, pp. 102-110. ISBN: 978-1-937284-38-1. pdf
Коева и др. 2012b: Koeva, Svetla, Borislav Rizov, Ekaterina Tarpomanova, Tsvetana Dimitrova, Rositsa Dekova, Ivelina Stoyanova, Svetlozara Leseva, Hristina Kukova, and Angel Genov (2012b) "Bulgarian-English Sentence- and Clause-Aligned Corpus" – In: Proceedings of the Second Workshop on Annotation of Corpora for Research in the Humanities (ACRH-2), Lisbon, 29 November 2012., Lisboa: Colibri, 2012, pp. 51-62. ISBN: 978-989-689-273-9. pdf
Коева и Генов 2011: Koeva, Sv., Genov, A. (2011) "Bulgarian Language Processing Chain." In Proceeding of the Workshop on the Integration of Multilingual Resources and Tools in Web Applications in conjunction with GSCL 2011, 26 September 2011, Hamburg.