Уеб базирани услуги на СКЛ
Общо описание
Българската многокомпонентна система за първична обработка и лингвистична анотация на текстове включва следните видове езикова обработка:• разделяне на изречения; • токънизация; • автоматично определяне на частта на речта и на граматичните характеристики на думите; • лематизация (автоматично определяне на основната форма).
Тагерът BgTagger
Тагерът определя най-вероятната част на речта за дадена дума в конкретен контекст и ѝ приписва еднозначна морфосинтактична информация. Тагерът е базиран на Метода на опорните вектори (Support Vector Machines) и предсказва частта на речта въз основа на множество от характеристики, които описват думата и нейния контекст. Тези характеристики включват:
• думи, дву- и триграми от думи в контекст от няколко токъна вляво и вдясно спрямо тагираната словоформа;
• тагове за частта на речта, дву- и триграми от такива тагове в определения контекстов прозорец;
• информация за суфикси, префикси, главни букви, сричкопренасяне и др. за думи, които не са неразпознати от речника.
Тагерът е трениран и тестван върху корпус, в който частите на речта и граматичните характеристики на думите са определени от експерти (БулПосКор). Стратегията за трениране има следните параметри: (i) две обхождания вляво и вдясно; (ii) контекстов прозорец от пет токъна, като тагираната дума е на втора позиция; (iii) дву- и триграми от думи или части на речта, лексикални параметри като префикси, суфикси, граница на изречение, главни букви и др.
Тренираният езиков модел е използван за еднозначно приписване на част на речта и морфосинтактични характеристики в корпуси от текстове на български език. Програмата има точност от 96,58%.
Българският лематизатор
Българският лематизатор определя основната форма на думите и ѝ преписва подробна граматична информация. Лематизацията се базира на резултата от тагирането и информацията от Граматичния речник. За тагирането се използва редуциран тагсет (75 класа в съпоставка с 1029 уникални граматични тага в речника), компилиран по начин, който осигурява минималната необходима информация за еднозначно съотнасяне със съответната лема. За разрешаване на многозначността се прилагат малък брой правила и ограничения.
Други компоненти
• програми за допълнителни нива на обработка и анотация;
• програми за анотация и съотнасяне на паралелни текстове на изреченско и подизреченско ниво.
Достъпност
За осигуряването на лесен достъп до програмите за предварителна обработка и лингвистична анотация на български текстове е създадена високо скалируема уеб инфраструктура. Предвидени са три нива на достъп до системата:• достъп чрез интернет - подходящ за потребители, които извършват обработване на относително малки по обем данни еднократно или рядко;
• достъп чрез RESTful API - подходящ за разработчици на софутер, които желаят да интегрират програмите за лингвистична обработка в софтуерни приложения;
• асинхронен достъп - подходящ за времеемки задачи, каквато е обработката на големи по обем корпуси; при този тип достъп потребителят предоставя за обработка архивирания корпус чрез интерфейса на уеб инфраструктурата; при приключване на задачата системата уведомява автоматично потребителя чрез имейл, след което той може да изтегли анотирания корпус.
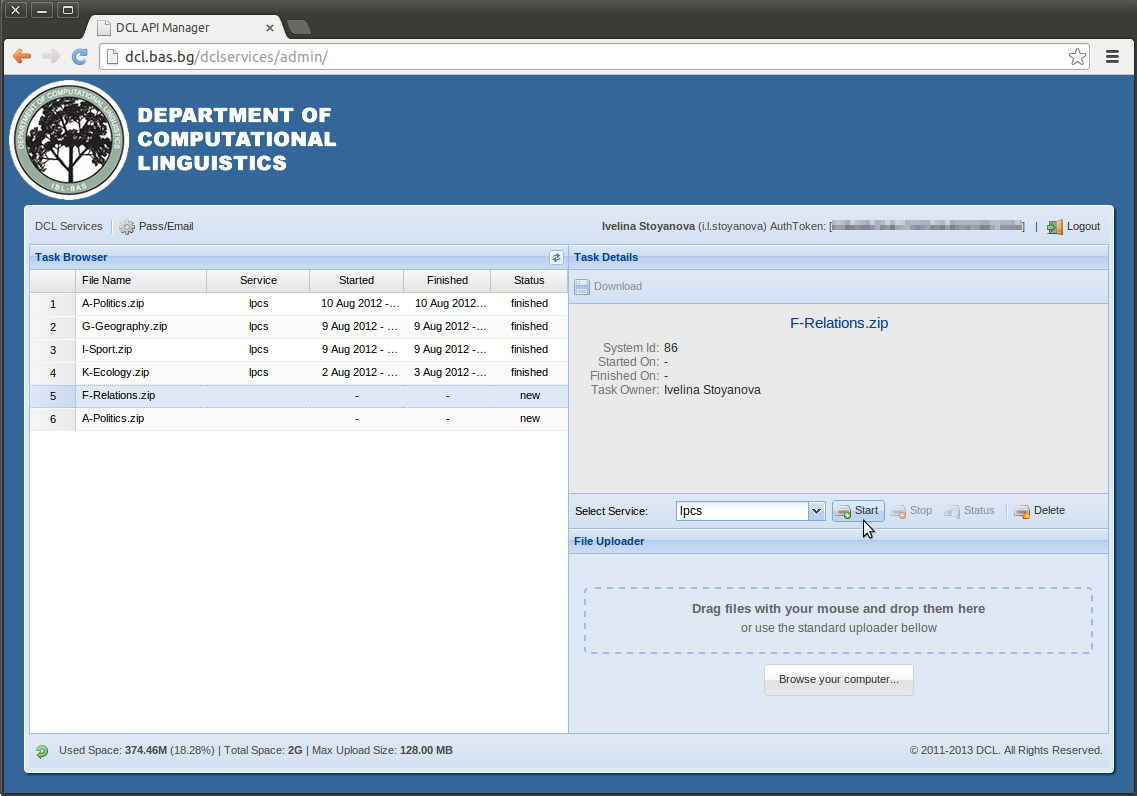
Фиг. 1. Интерфейсът за асинхронни задачи на уеб инфраструктурата
Предимства
Основните предимства на уеб инфраструктурата са следните:
• позволява висококачествена лингвистична обработка на езикови ресурси за български език;
• осигурява комплексна и взаимно съвместима анотация на различни езикови нива;
• имплементирана с най-съвременните технологии;
• осигурява различни нива на достъп в съответствие с нуждите на различните потребители;
• високо скалируема, позволява разпределение на процесите на различни компютри.
Системни характеристики
• Език на програмиране: C++. PHP;
• Платформа на изпълнение: Linux
Условия за достъп
Уеб базирана инфраструктура за лингвистична обработка на данни на български език се предоставя при заявка след направена регистрация. За да се регистрирате, изпратете имейл на адрес: dcl@dcl.bas.bg
Публикации
Koeva, Sv., Genov, A. Bulgarian Language Processing Chain. In Proceeding of the Workshop on the Integration of Multilingual Resources and Tools in Web Applications, 26 September 2011, Hamburg.
Документация
По-подробна информация и инструкции за използване на инфраструктурата са описани в Ръководството за използване на уеб интерфейса.