Български национален корпус
Българският национален корпус е създаден в Института за български език „Проф. Любомир Андрейчин” от сътрудници от Секцията по компютърна лингвистика и Секцията за българска лексикология и лексикография. В него са обединени няколко отделни електронни корпуса, разработени в периода 2001-2009 г. за целите на двете секции. Корпусът непрекъснато се обогатява с нови текстове.
Българският национален корпус се състои от едноезикова българска част и 47 паралелни корпуса с различна големина. Българската част съдържа 1.2 милиарда думи и включва над 240 000 текста. Материалите в Корпуса отразяват състоянието на българския език (предимно в неговата писмена форма) от средата на ХХ в. (1945 г.) до наши дни.
Българският национален корпус дава възможност за редица приложения в различни области на езикознанието: в компютърната лингвистика; в лексикографията; за теоретични изследвания на определени лингвистични явления; за наблюдения върху особеностите на отделни области на езика; за извличане на примери за демонстрация при обучението по български език и др. Ето някои по-конкретни възможни приложения на Корпуса:
Извличане на специални или общи подкорпуси по определени критерии (тематика, автор, година / период на издаване, източник и др.), които да бъдат използвани като тренировъчни корпуси за редица приложения – граматично и семантично тагиране и пр., както и за други изследователски цели.
Наблюдения върху честотата на употреба на думи или езикови конструкции, генериране на честотни списъци и др.
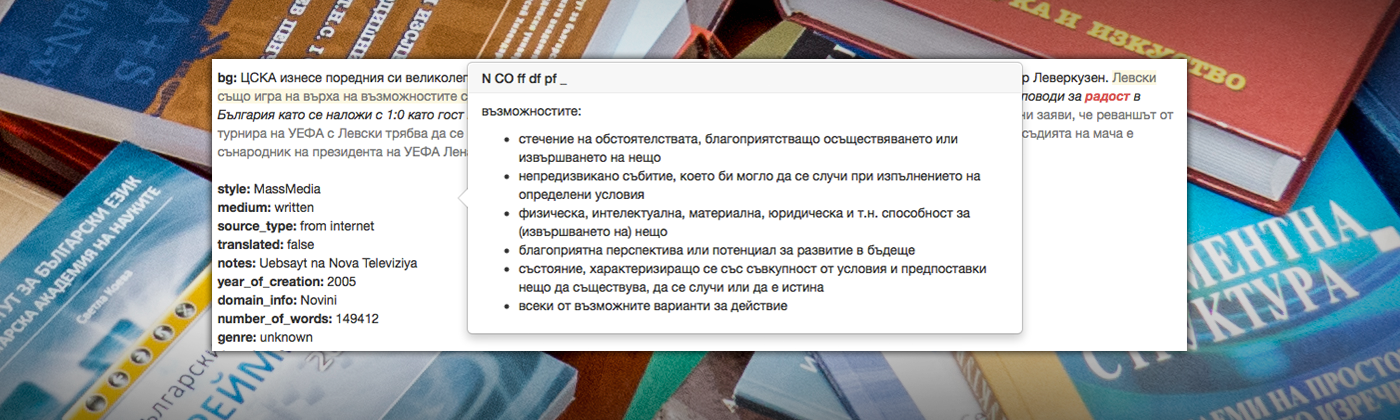
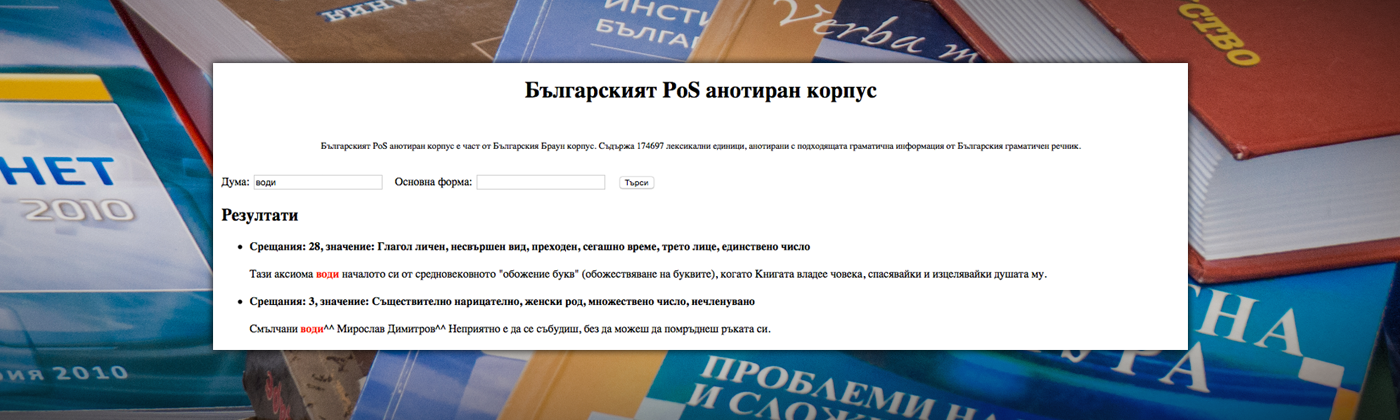
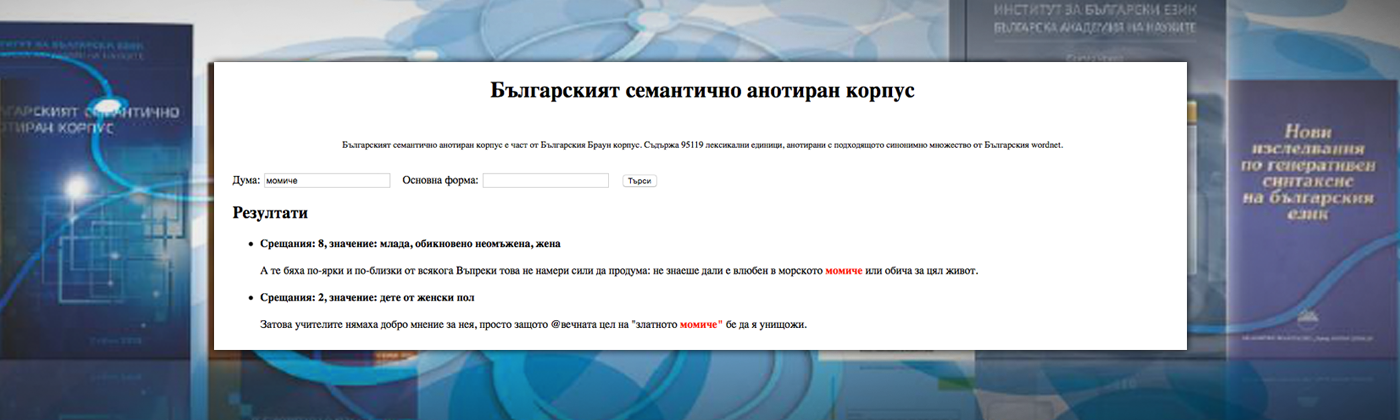
Търсене в Корпуса на примери за определени лингвистични явления с цел лингвистично описание, лексикографско отразяване или с учебна цел в обучението по български език (достъпно за ползване в интернет).