Bulgarian National Corpus
The Bulgarian National corpus is created at the Institute for Bulgarian Language „Prof. L. Andreychin” by research associates from the Department of Computational Linguistics and the Department of Bulgarian Lexicology and Lexicography. It incorporates several individual electronic corpora, developed in the period 2001-2009 for the purposes of the two departments. The corpus is constantly enlarged with new texts.
The Bulgarian National corpus consists of a monolingual (Bulgarian) part and 47 parallel corpora. The Bulgarian part includes about 1.2 billion words in over 240 000 text samples. The materials in the Corpus reflect the state of the Bulgarian language (mainly in its written form) from the middle of 20th century (1945) until present.
The Bulgarian National Corpus enables a number of applications in various linguistic areas: in computational linguistics; in lexicography; within theoretical studies of specific linguistic phenomena; for observations of the characteristics of individual language domains; for extracting exemplary sentences for the education in Bulgarian language, etc. Some of the more specific applications of the Corpus are listed below:
Extraction of specific or general sub-corpora following particular criteria (subject, author, year / period of publication, source, etc), which could be used as training corpora for a number of applications – grammatical and semantic tagging, among others, as well as for other research purposes.
Observations on the usage frequency of words or language constructions, generation of frequency lists, etc.
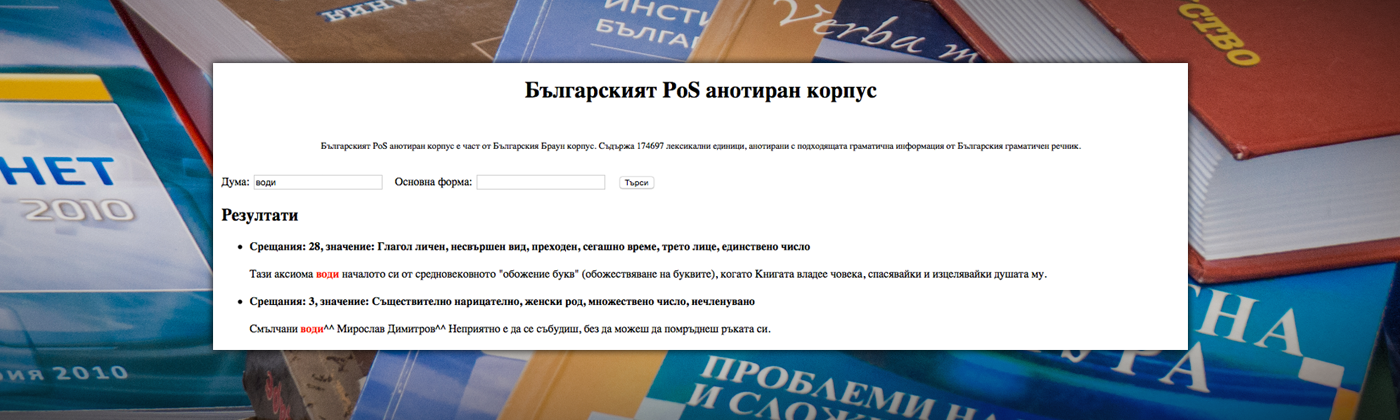
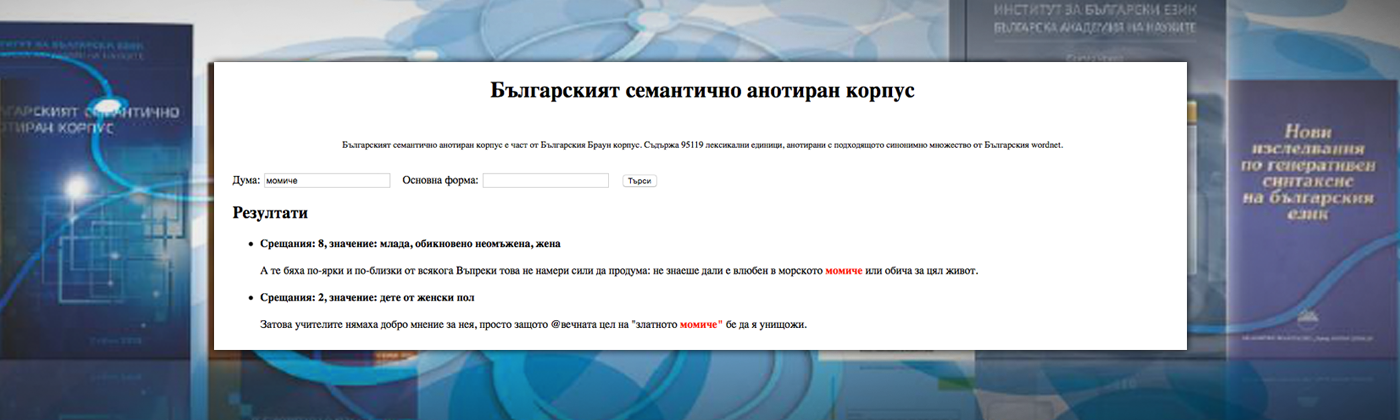
Searches in the Corpus for instances of particular linguistic phenomena, lexicographic examples or for educational purposes in the Bulgarian language instruction (available to use over the Internet).