Българско-английският паралелен корпус със съотнесени (прости) изречения (БулЕнСИ) е структуриран корпус с паралелни текстове на български и английски език, в рамките на който съответстващите си по съдържание изречения и прости изречения в състава на сложните са съотнесени помежду си. Извършена е и анотация на вида на синтактичната връзка между двойките прости изречения в състава на сложното. Корпусът е създаден от екип от Секцията по компютърна лингвистика към Института за български език „Проф. Любомир Андрейчин“ при Българската академия на науките.
Езици: български, английски.
Тип: паралелен двуезиков текстов корпус, обогатен с лингвистична анотация.
Състав: БулЕнСИ съдържа общо 366 865 токъна, като българският подкорпус включва 176 397 токъна, а английският подкорпус – 190 468 токъна.
Анотация: токънизация, лематизация, разделяне на изречения и прости изречения в сложните, съотнасяне на изречения и прости изречения в сложните между двата езика, определяне на вида на синтактичната връзка.
Условия за достъп: Свободно изтегляне с лиценза Криейтив комънс признание – Споделяне на споделеното (Creative Commons Attribution-ShareAlike 4.0 International, CC BY-SA 4.0).
ПРОЕКТИ
Национално финансиран проект „Електронни езикови ресурси и програми за тяхната обработка (БулНет и Фреймнет)“ (2011– 2013)
CESAR: Central and South-east europeAn Resources (Езикови ресурси за езиците от Централна и Югоизточна Европа), проект, финансиран от Европейската комисия
УЧАСТНИЦИ
проф. д-р Светла Коева (ръководител)
гл. ас. д-р Цветана Димитрова, гл. ас. д-р Христина Кукова, гл. ас. д-р Светлозара Лесева, доц. д-р Екатерина Търпоманова, гл. ас. д-р Росица Декова (външен сътрудник за определен период) (анотатори)
Борислав Ризов (автор на програмата за анотация)
д-р Ивелина Стоянова, Ангел Генов (компилация на изходния корпус)
Общо описание
Българско-английският паралелен корпус със съотнесени (прости) изречения (БулЕнСИ) е подкорпус на Българско-английския паралелен корпус в рамките на Българския национален корпус. Текстовете в БулЕнСИ са разделени в следните категории: административни текстове (20,5%); художествена литература (21,35%); публицистика (37,13%); научни текстове (11,16%); разговорни / художествени текстове (9,84%). Разнообразието на езиковите данни позволява да се правят прогнози и изводи за представянето на различни методи за обработка на данни при различни текстове. Българският подкорпус съдържа 14 667 изречения (със средна дължина на изречениe 12,02 думи), а английският подкорпус – 15 718 изречения (със средна дължина на изречение 12,11 думи). Средният брой на простите изречения в състава на сложното е 1,67 за български и 1,85 за английски.
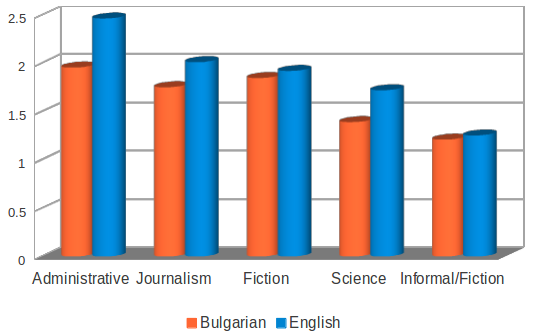
Среден брой прости изречения в рамките на изречението в български и английски език по стиловеAverage length of Bulgarian and English sentences (in terms of number of clauses) across the different styles
Анотация
Частичната синтактична анотация на Българско-английския паралелен корпус със (прости) съотнесени изречения включва:
а) определяне на границите на изреченията и на простите изречения в състава на сложното;
б) определяне на вида на връзката (съчинителна или подчинителна) между простите изречения в състава на сложното;
в) идентификация на лингвистичните маркери, които въвеждат простите изречения в състава на сложното – съчинителни и подчинителни съюзи, съюзни наречия, местоименни съюзи, пунктуационни знаци и др.
Текстовете на български език са токънизирани, разделени на изречения и лематизирани с помощта на Българската многокомпонентна система за първична обработка и лингвистична анотация на текстове, а за английски език са използвани Апаче ОпънЕНеЛПи (Apache OpenNLP) (за разделяне на изречения) и Станфорд КорЕнЕлПи (Stanford CoreNLP) (за токънизация и лематизация). Съотнасянето на изреченията в двата езика е извършено автоматично с помощта на ХунАлайн (HunAlign), с последваща ръчна проверка.
Разделянето на простите изречения в състава на сложното в подкорпусите за двата езика, съотнасянето на съответстващите си прости изречения в български и в английски, определянето на синтактичната връзка между тях, както и проверката и корекцията на автоматичното съотнасяне са извършени от експерти с помощта на специално разработена програма – „Анафора“ (Anaphora). Съотнасянето между прости изречения се извършва в рамките на двойка паралелни самостоятелни изречения. Преобладаващият модел при съотнесените прости изречения в състава на сложното е 1:1.
Формат на корпуса
Текстовите данни от Българско-английския паралелен корпус със съотнесени (прости) изречения (БулЕнСИ) се съхраняват в плитък xml формат, който е подходящ за представяне на дистантно разположени конституенти на фразата или на простото изречение. Форматът е ефективен за представяне на анотацията и на синтактичната йерархия между двойките прости изречения чрез посочване на вида на съюзната връзка помежду им.
Българските текстове са в .txt файлове, а паралелните английски текстове са във файлове с разширение .al. Текстовете са представени като поредица от xml елементи от типа <word>. На всеки <word> елемент са приписани атрибути, съдържащи следната информация:
1. Лексикална (равнище на лематизация) – чрез атрибутите l (lemma, лема) и w (word, дума), чиито стойности съдържат съответно лемата и словоформата, например l="подам", w="подаде".
2. Синтактична (равнище на простото изречение в състава на сложното) – атрибутът cl (clause, просто изречение в състава на сложното) има стойност идентификационния номер на простото изречение, в което се появява дадена словоформа.
3. Съотнасяне – атрибутът cl_al (aligned clauses, съотнесени прости изречения) съдържа идентификационния номер на съотнесените прости изречения в състава на сложните и се приписва към първата дума в простото изречение; атрибутът sen (sentence, изречение) съдържа идентификационния номер на изречението и се приписва към последната дума в изречението, придружаван от атрибута e (end, край) за край на изречение (винаги със стойност True), например:
<word cl="183377292" cl_al="df14adf988f4412683683056b5a2c397" l="протокол" w="Протокол"/>
<word cl="183377292" l="за" w="за"/>
<word cl="183377292" l="опазване" w="опазване"/>
<word cl="183377292" l="на" w="на"/>
<word cl="183377292" l="средиземен" w="средиземно"/>
<word cl="183377292" l="море" w="море"/>
<word cl="183377292" l="от" w="от"/>
<word cl="183377292" l="замърсяване" w="замърсяване"/>
<word cl="183377292" l="от" w="от"/>
<word cl="183377292" l="наземен" w="наземни"/>
<word cl="183377292" e="True" l="източник" sen="e38b171675e6485881f58a2004634777" w="източници"/>
4. Синтактична (свързване на прости изречения в състава на сложното) – атрибутът cl2 съдържа като стойност идентификационния номер на простото изречение, с което даденото просто изречение е свързано съчинително или подчинително; включва се като атрибут при първата дума на просто изречение, което е част от сложно. Към същата дума се включва и атрибутът m, чиято стойност отбелязва вида на връзката между двете прости изречения cl и cl2, съответно – съчинително свързване (N_N) и подчинително свързване (N_S; _SN), където са използвани следните означения: N (nuclear, главно или съчинено изречение в зависимост от изразяваното отношение) и S (satellite, подчинено изречение), например:
<word cl="183392332" cl2="183392044" cl_al="5578f961cb374c59aa20ae14d02a3c45" l="да" m="N_S" w="да"/>
Стойността на атрибута m показва и мястото на подчиненото изречение спрямо главното: N_S означава, че подчиненото изречение следва главното или е вмъкнато в него, а _SN – че подчиненото изречение предхожда главното.
Атрибутът p се използва за означаването на сложни съюзи; той получава еднаква стойност за всяка една от съставящите съюза думи, като към стойността при първата дума се добавя :0, а към втората – :1, и т.н, например:
<word w="за" l="за" p="1:0" m="N_S" />
<word w="да" l="да" p="1:1" />.
Празните думи (w="====") са формални елементи, които се появяват в началото на простото изречение, ако свързващият елемент не е експлицитно изразен или ако връзката е изразена чрез пунктуационен знак.
Пунктуационните знаци не са отделени като самостоятелни токъни, а са анотирани заедно с предхождащия ги токън.
Българско-английският паралелен корпус със съотнесени (прости) изречения (БулЕнСИ) може да се използва за:
- разработване на методи за автоматично разделяне и съотнасяне на изречения и прости изречения в състава на сложното;
- разработване на методи за промяна на словореда на простите изречения в състава на сложното с оглед на оптимизиране на тренировъчните данни за целите на автоматичния превод;
- съотнасяне на ниво думи и фрази;
- приложения за разрешаване на семантична многозначност.
В Секцията по компютърна лингвистика е разработена програма за разпознаване на границите на прости изречения в състава на сложното КлoзСплитър (Clause Splitter), базирана на правила, а Корпусът е използван за тестване на програмата.
Ресурсът се предоставя за свободно използване с лиценз CC BY-SA 4.0. Цитирайте в разработките си, основани на БулЕнСИ, някоя от следните публикации:
- Търпоманова, Ек., Цв. Димитрова. Българско-английски паралелен корпус със съотнесени (прости) изречения. – В: Езикови технологии и ресурси за български език. Коева, Св. (ред. и съст.) София, Академично издателство „Проф. Марин Дринов“, 2014, с. 105–126. pdf
- Koeva, S., B. Rizov, E. Tarpomanova, Ts. Dimitrova, R. Dekova, I. Stoyanova, S. Leseva, H. Kukova, and A. Genov. Bulgarian-English Sentence- and Clause-Aligned Corpus. – In: Proceedings of the Second Workshop on Annotation of Corpora for Research in the Humanities (ACRH-2). Lisboa: Colibri, 2012, 51–62. pdf
- Koeva, S., B. Rizov, E. Tarpomanova, Ts. Dimitrova, R. Dekova, I. Stoyanova, S. Leseva, H. Kukova, and A. Genov. Application of Clause Alignment for Statistical Machine Translation. – In: Proceedings Sixth Workshop on Syntax, Semantics and Structure in Statistical Translation (SSST-6), Jeju, Republic of Korea. The Association for Computational Linguistics: ACL 2012 / SIGMT / SIGLEX Workshop, 2012, 102–110. pdf
- Rizov, B., R. Dekova. Anaphora – Clause Annotation and Alignment Tool. – In: Proceedings of the Demonstrations at the 14th Conference of the European Chapter of the Association for Computational Linguistics. Gothenburg: Association for Computational Linguistics, 2014, pp. 69–72. pdf






