Заглавие: Многоезиков корпус от изображения (MIC 21)
Срок: 2021
Финансиране: Многоезиковият корпус от изображения (MIC 21) се финансира по проекта Европейска езикова мрежа чрез конкурс за пилотни проекти. Проектът „Европейска езикова мрежа“ получава финансиране по програма „Хоризонт 2020“ за изследвания и иновации на Европейския съюз по договор No. 825627 (ELG).

Членове на екипа
Ръководител: проф. Светла Коева
Участници: проф. Светла Коева, д-р Ивелина Стоянова, Йордан Кралев, гл. ас. д-р Светлозара Лесева, гл. ас. д-р Валентина Стефанова, гл. ас. д-р Цветана Димитрова, гл. ас. д-р Мария Тодорова, Христина Кукова, Виктория Петрова, Кристиян Любенов, Кръстьо Гигов.
Резюме:
Многоезиковият корпус с изображения съдържа голяма колекция от обекти в тематично свързани изображения, които са анотирани със сегментационни маски, класифицирани в съответствие с класовете, дефинирани в специално разработената Онтология на визуалните обекти. Колекцията от данни има приложение както за класификацията на изображения и откриването на обекти в тях, така и за задачи, включващи семантична сегментация. Основните приноси на екипа по проекта са: а) предоставянето на голяма колекция от висококачествени изображения, които са достъпни за свободно ползване; б) формулирането на Онтология на визуалните обекти, основаващи се на йерархията на съществителните в Уърднет; в) прецизната ръчна корекция на автоматично сегментираните обекти в изображенията и ръчната анотация на класовете обекти; и г) съотнасянето на обектите и изображенията с подробно многоезиково описание, основаващо се на вътре- и междуезикови релации в Уърднет.
Преходът от използването на традиционни методи за обработка на данни към нови подходи в резултат от необходимостта от големи по обем колекции с многомодално съдържание мотивира създаването на нов тип ресурс с изображения – Многоезиковия корпус с изображения (MIC 21). Корпусът се характеризира с внимателно подбрани изображения, илюстриращи тематично свързани области, и прецизна анотация за целите на сегментирането и класификацията на обектите в изображенията.
Основната цел на проекта е създаването на корпус с изображения със следните основни характеристики: а) богато съдържание, включващо хиляди изображения и анотирани обекти; б) множество от използвани при анотацията класове, принадлежащи към специално разработена Онтология на визуалните обекти; в) оценена и коригирана от експерти автоматична сегментация и класификация на обектите; г) множество от класовете на обектите от Онтологията, всеки от които е снабден с дефиниция на съответния концепт и превод на класа и дефиницията на най-малко 20 езика. Важна характеристика на корпуса с голямо въздействие върху разработването на различни приложения е свободното разпространение на включените в корпуса данни.
С оглед на оптимизирането на ръчната анотация бе създадена многокомпонентна система за за откриване и сегментация на обектите в изображенията, основаваща се на предварително обучени модели. Бе разработена и надеждна услуга за автоматично анотиране на обектите в изображенията с помощта на технологии за контейнеризация, трениране и претрениране на модели и свързване на съществуващи инструменти и платформи за машинно обучение. Важна част от разпространението на резултатите от проекта бе ангажирането на различни професионални общности в дискутирането на актуалните решения и практики в областта на изкуствения интелект, както и демонстрирането и популяризирането на дейността на Европейската езикова мрежа и на проекта MIC21.
В основната си част целите на проекта са ориентирани към постигането на резултати с пряка приложимост в областта на автоматичното разпознаване и анотиране на обекти в изображения (предпоставка за ефективно търсене на обекти в изображения и видео съдържание) и автоматичното анотиране на изображения, придружени с кратки описания на различни европейски езици.
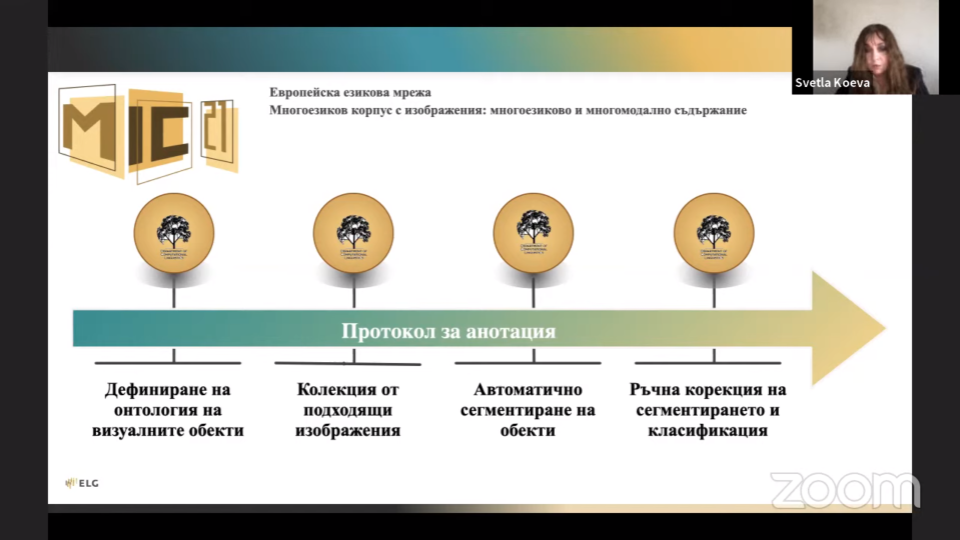
Процесът по анотиране включва четири основни етапа: а) дефиниране на Онтология на визуалните обекти; б) събиране на подходящи изображения; в) автоматично сегментиране и класификация на обектите в изображенията; и г) ръчна корекция и класификация на сегментираните обекти. Корпусът съдържа изображения от 4 тематични области (Спорт, Транспорт, Изкуства и Сигурност), в които са групирани характеризиращи ги доминантни класове като тенисист, футболист, лимузина, такси, певец, цигулар, пожарна кола и полицейска лодка, организирани в 130 подмножества от изображения. За анотацията е използвана системата COCO Annotator, която дава възможност за едновременен достъп от страна на множество потребители.
| Тематични области | Брой колекции | Брой изображения | Брой анотации |
| СПОРТ | 40 | 6,915 | 65,482 |
| ТРАНСПОРТ | 50 | 7,710 | 78,172 |
| ИЗКУСТВО | 25 | 3,854 | 24,217 |
| СИГУРНОСТ | 15 | 2,837 | 35,916 |
| ОБЩО | 130 | 21,316 | 203,787 |
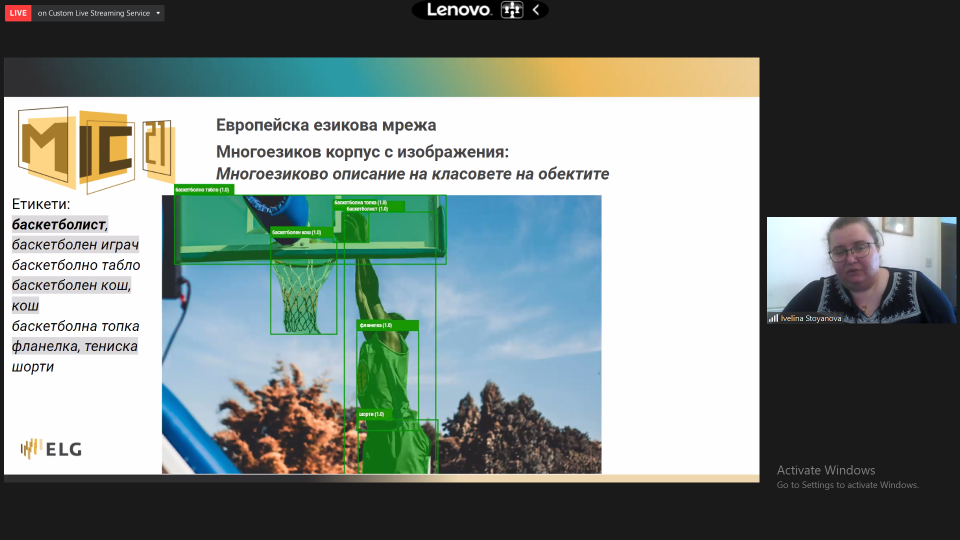
Многоезиковият корпус с изображения съдържа голям набор от обекти в изображения, анотирани със сегментационни маски и класифицирани в съответствие с класовете в специално разработената базирана на Уърднет Онтология на визуалните обекти. По този начин се осигуряват данни за трениране на модели за целите на разпознаването на обекти, сегментацията и класификацията им. Онтологията съдържа множество от класове (706 класа, съответстващи на анотираните визуални обекти, и 147 класа, кореспондиращи с техните хипероними), релации и аксиоми. Класовете съответстват на (но не се ограничават до) дефинираните в Уърднет концепти, които могат да се представят чрез визуални обекти. Част от релациите и техните свойства също са заимствани от Уърднет. Аксиомите служат за моделиране на твърдения, които са верни във всички случаи. Онтологията на визуалните обекти позволява лесната интеграция на анотираните изображения в различни бази данни, както и изучаването на връзките между обекти в изображенията.
В корпуса са включени изображения, подбрани от колекции от различни онлайн хранилища, предлагащи достъп чрез API: Wikimedia; Pexels; Flickr; Pixabay. Като източник на изображения е използвана и програмният интерфейс на Creative Commons Search API. Всяко изображение е снабдено с метаописание във формат JSON (пример). Метаданните включват следната информация: име на колекцията от данни, път до файла, принадлежност към дадено подмножество от изображения, идентификатор на подмножеството от изображения, автор на изображението, URL адрес на автора, оригинален размер на изображението, име на файла, идентификатор на изображението, лиценз, под който се разпространява изображението, източник на изображението, последен достъп до URL адреса на източника, име на източника, URL адрес на източника, лиценза на MIC21, кой предоставя MIC21, цитиране на проекта MIC21, MIC21: контакти, интернет адрес на проекта MIC21.
За оптимизиране на ръчната анотация бе разработена многокомпонентна система за откриване и сегменация на обектите в изображенията. За генериране на предложенията за анотация са използвани два софтуерни пакета – YOLACT и Detectron2 и Fast R-CNN модели, тренирани върху колекцията от анотирани данни COCO.
Класовете на специално разработената Онтология на визуалните обекти са преведени на 25 езика (английски, албански, баски, български, галисийски, гръцки, датски, исландски, испански, италиански, каталунски, литовски, немски, нидерландски, полски, португалски, румънски, руски, сръбски, словашки, словенски, финландски, френски, хърватски и шведски). За целта са използвани свободно достъпните уърднети, предоставени в рамките на проекта Разширен свободно достъпен многоезиков уърднет (Extended Open Multilingual WordNet). За класовете в онтологията, които нямат съответствие в Уърднет, са използвани техни подходящи хипероними. При липса на преводен еквивалент в Уърднет, са използвани допълнителни източници на преводни съответствия, като БейбълНет (BabelNet). Многоезиковите преводни еквиваленти на класовете са представени в отделен файл в JSON формат, който съдържа информация за езика и източника на съответния преводен еквивалент (пример). Заедно с преводните еквивалентни на класовете от разработената онтология са представени и техните синоними, дефиницията на концепта и примери за употребата (в случаите, в които такива са включени в източниците). Експлицитното съотнасяне на обектите и изображенията с подходящи текстови фрагменти има приложение за задачи, свързани с автоматичното генериране на многоезиково описание на изображения, съотнасянето между изображение и текст, автоматичното отговаряне на въпроси върху съдържанието на изображения и видеозаписи.
Разработена е Платформа за оценка и прилагане на моделите, разработени по MIC21, основаваща се на системата за създаване на колекции от данни и модели FiftyOne и софтуерните пакети Yolact и Detectron2. За имплементацията е използван моделът Mask R-CNN (с помощта на Python3, API за дълбоко учене Keras и библиотеката TensorFlow). За целта е извършено предварително трениране на модели за Fast R-CNN с помощта на системата Detectrоn2, в резултат от което са получени 130 модела (пример), генериращи ограждащи полета и сегментационни маски за всеки обект от даден клас, който се среща в изображението. Платформата поддържа функционалност с приложно-програмен интерфейс (API) за обработка на нови изображения с всеки от следните три модела: Yolact, Detectron2 и MIC21. Платформата за оценка и прилагане на моделите MIC21 е достъпна с лиценза Криейтив Комънс Признание – Споделяне на споделеното (Creative Commons Attribution-ShareAlike 4.0 International, CC BY-SA 4.0) чрез платформата на Европейската езикова мрежа. На следния адрес можете да се запознаете с демонстрация на колекцията от данни MIC21 и Платформата за оценка и прилагане на моделите, разработени по MIC21.
Създадените в рамките на проекта MIC21 модели и работни изображения се съхраняват в специално хранилище MIC21. Колекцията от данни (изображенията, работните им варианти, метаданните към изображенията, анотациите, класовете на разработената онтология и многоезиковите преводни еквиваленти на класовете от онтологията) се разпространяват с лиценза Криейтив Комънс Признание – Споделяне на споделеното (Creative Commons Attribution-ShareAlike 4.0 International, CC BY-SA 4.0) чрез платформата на Европейската езикова мрежа и хранилището на MIC21.
Първото събитие за популяризиране на Европейската езикова мрежа (ELG) в България се проведе на 11.02.2022 г. В него взеха участие 121 души от академичните среди – Българската академия на науките (15 души) и различни университети (48 души), представители на институциите на Европейския съюз или Европейската комисия (5), български правителствени агенции (6), технологични компании (31) и медии (6). Информация за събитието, свързано с популяризиране на Европейската езикова мрежа (ELG), беше широко разпространена чрез страниците на Секцията по компютърна лингвистика (DCL) и Института за български език към БАН (IBL), чрез кампании във Facebook и LinkedIn и покани до широк списък със заинтересовани лица от бизнеса и научните среди, работещи в сферата на информационните технологии. Събитието се излъчи на живо чрез канала на Секцията по компютърна лингвистика в Ютюб, като записът има над 300 гледания. Провеждането на събитието е отразено в 2 интервюта, дадени от проф. Светла Коева по БНР на 10.02.2022 г. и на 16.02.2022 г.
Галерия
 |
 |
 |
 |
 |
 |
 |
 |
 |
Публикации
Koeva, S. Multilingual Image Corpus: Annotation Protocol. Proceedings of the International Conference on Recent Advances in Natural Language Processing (RANLP 2021), Publisher: INCOMA Ltd., 2021, ISBN:978-954-452-072-4, ISSN:1313-8502; series eISSN 2603-2813, DOI:https://doi.org/10.26615/978-954-452-072-4_080, 701-707.
Koeva, S., I. Stoyanova, Y. Kralev. Multilingual Image Corpus – Towards a Multimodal and Multilingual Dataset. In: Proceedings of the Language Resources and Evaluation Conference (LREC 2022). European Language Resources Association. (pdf)
Участие на конференции
Koeva, S. Multilingual Image Corpus, The Third Annual ELG Conference META-FORUM 2021, 15.11.2021 (pdf)
Koeva, S. Multilingual Image Corpus: Annotation Protocol. International Conference on Recent Advances in Natural Language Processing (RANLP 2021), 03.09.2021 (pdf)
Koeva, S., I. Stoyanova, Y. Kralev. Multilingual Image Corpus – Towards a Multimodal and Multilingual Dataset. Language Resources and Evaluation Conference (LREC 2022). June 2022. (video)






