The Bulgarian-English Sentence- and Clause-Aligned Corpus (BulEnAC) is a parallel corpus of aligned Bulgarian and English sentences and clauses with annotation of the syntactic relation between clauses. The corpus was developed at the Department of Computational Linguistics of the Institute of Bulgarian Language “Prof. Lyubomir Andreychin” at the Bulgarian Academy of Sciences.
Languages: Bulgarian, English.
Type: bilingual parallel corpus, annotated.
Size: BulEnAC contains 366 865 tokens, distributed as follows: 176 397 tokens in the Bulgarian subcorpus, and 190 468 tokens in the English subcorpus.
Annotation: tokenisation, lemmatisation, sentences and clauses splitted and aligned, annotation of the syntactic relations.
Access: Downloadable under Creative Commons Attribution-ShareAlike 4.0 International license (CC BY-SA 4.0).
Projects
Nationally funded project Electronic language resources and processing tools (BulNet and FramNet) (2011– 2013)
CESAR: Central and South-east europeAn Resources, funded by the European Commission
Participants
prof. Svetla Koeva (head of the project and principal investigator)
Tsvetana Dimitrova, Hristina Kukova, Svetlozara Leseva, Ekaterina Tarpomanova, Rositsa Dekova (external collaborator for a period of time) (annotation)
Borislav Rizov (development of the annotation application)
Ivelina Stoyanova, Angel Genov (corpus compilation)
General description
Bulgarian-English Sentence- and Clause-Aligned Corpus (BulEnAC) is a subcorpus of the Bulgarian-English Parallel Corpus within the Bulgarian National Corpus. The texts in BulEnAC cover five categories: administrative texts (20.5%); fiction (21.35%); journalism (37.13%); science (11.16%); informal texts (9.84%). The diversity of the data helps withfor prognostics on the performance of data processing methods on different texts. The Bulgarian subcorpus contains 14,667 sentences (with an average sentence length of 12.02 words), while the English subcorpus includes 15,718 sentences (with an average sentence length of 12.11 words). The average number of clauses per sentence is 1.67 for Bulgarian and 1.85 for English.
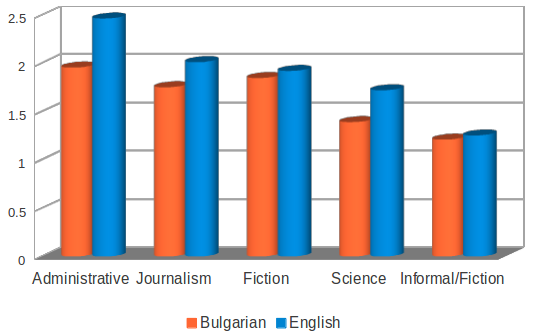
Average length of Bulgarian and English sentences (in terms of number of clauses) across the different styles
Annotation
The syntactic annotation of BulEnAC involves:
a) sentence and clause splitting;
b) annotation of the type of syntactic relation (coordinate or subordinate) between clauses.
c) marking the elements that introduce the clause: conjunctions, subjunctions, and punctuation.
Bulgarian texts are tokenised, sentence splitted and lemmatised with the Bulgarian Language Processing Chain, while English texts were processed with Apache OpenNLP (for sentence splitting) and Stanford CoreNLP (for tokenisation and lemmatisation). HunAlign was used for automatic sentence alignment ion both languages, which was followed by manual verification.
Clause splitting and alignment and the annotation of the syntactic relation for both languages, as well as the verification and editing of the automatic sentence splitting and alignment were done by linguists with the Anaphora application. Clause alignment is done within the parallel sentences, which were also aligned. The predominant pattern in aligned clauses is 1:1.
Format
Texts in BulEnAC are in flat xml format which is suitable for representing distant constituents, as well as for the syntactic hierarchy between the clause pairs and the syntactic relation.
Bulgarian files are in .txt while the parallel English files are in .al format. Each word is represented as an xml element of type <word>. Each <word> element is defined by a set of attributes that correspond to different annotation level:
1. Lexical level (lemmatisation): the attributes l (lemma) and w (word) are for the wordform and the lemma, respectively, e.g. l="подам", w="подаде".
2. Syntactic (clause level): the attribute cl (for clause) contains the id of the clause in which the <word> occurs.
3. Alignment: the attribute cl_al (for aligned clauses) contains the id of the aligned clauses and is assigned to the first <word> in the clause; the attribute sen (for sentence) contains the id of the sentence – it is assigned to the last <word> in the sentence and is accompanied by the attribute e (end) for the sentence end (which is always of True value), e.g.
<word cl="183377292" cl_al="df14adf988f4412683683056b5a2c397" l="протокол" w="Протокол"/>
<word cl="183377292" l="за" w="за"/>
<word cl="183377292" l="опазване" w="опазване"/>
<word cl="183377292" l="на" w="на"/>
<word cl="183377292" l="средиземен" w="средиземно"/>
<word cl="183377292" l="море" w="море"/>
<word cl="183377292" l="от" w="от"/>
<word cl="183377292" l="замърсяване" w="замърсяване"/>
<word cl="183377292" l="от" w="от"/>
<word cl="183377292" l="наземен" w="наземни"/>
<word cl="183377292" e="True" l="източник" sen="e38b171675e6485881f58a2004634777" w="източници"/>
4. Syntactic (clause alignmentalingment): the attribute cl2 contains the id of the clause with which the current clause is connected; it is assigned as an attribute to the first word of the clause that is part of a sentence. The same word has an attribute m with values for the type of relation: cl for coordinate conjunctions (N_N) and cl2 for subordinate conjunctions (N_S; _SN), where: N (nuclear) is for the main clause or for clauses in a coordinate sentence; S (satellite) is for the subordinate clauses, e.g.
<word cl="183392332" cl2="183392044" cl_al="5578f961cb374c59aa20ae14d02a3c45" l="да" m="N_S" w="да"/>
The value of the attribute m defines the position of the subordinate clause with respect to the main one: N_S: subordinate clause follows the main one (or splits it); _SN: subordinate clause precedes the main one.
The attribute p is used for compound conjunctions: it has the same value for each token that is part of the conjunction, where :0 is added to the value of the first <word>, :1 is added to the value of the second <word>, etc., as in:
<word w="за" l="за" p="1:0" m="N_S" />
<word w="да" l="да" p="1:1" />.
Empty words (w="====") are added to the beginning of the clause if the syntactic relation is not explicit or if it is expressed by a punctuation mark.
Punctuation marks were not annotated as separate tokens but are part of the preceding token.
The applications of the Bulgarian-English Sentence- and Clause-Aligned Corpus (BulEnAC) involve:
- methods for automatic sentence and clause splitting and alignment;
- methods for changing the ordering of clauses to optimise the training data for automatic translation tasks; word and phrase alignment;
- word and phrase alignment; and
- word sense disambiguation.
A rule-based application for clause splitting ClauseSplitter was also developed and tested on the BulEnAC.
BulEnAC is freely downloadable under the license CC BY-SA 4.0. If you use the corpus, please cite any of the following publications:
- Tarpomanova, E., T. Dimitrova. Bulgarian-English parallel sentence- and clause-aligned corpus. – In: Koeva, S. (ed.) Language Technologies for Bulgarian. Sofia: Prof. Marin Drinov Academic publishers, 2014, pp. 105–126. [Търпоманова, Ек., Цв. Димитрова. Българско-английски паралелен корпус със съотнесени (прости) изречения. – В: Езикови технологии и ресурси за български език. Коева, Св. (ред. и съст.) София, Академично издателство „Проф. Марин Дринов“, 2014, с. 105–126.] pdf
- Koeva, S., B. Rizov, E. Tarpomanova, Ts. Dimitrova, R. Dekova, I. Stoyanova, S. Leseva, H. Kukova, and A. Genov. Bulgarian-English Sentence- and Clause-Aligned Corpus. – In: Proceedings of the Second Workshop on Annotation of Corpora for Research in the Humanities (ACRH-2). Lisboa: Colibri, 2012, 51–62. pdf
- Koeva, S., B. Rizov, E. Tarpomanova, Ts. Dimitrova, R. Dekova, I. Stoyanova, S. Leseva, H. Kukova, and A. Genov. Application of Clause Alignment for Statistical Machine Translation. – In: Proceedings Sixth Workshop on Syntax, Semantics and Structure in Statistical Translation (SSST-6), Jeju, Republic of Korea. The Association for Computational Linguistics: ACL 2012 / SIGMT / SIGLEX Workshop, 2012, 102–110. pdf
- Rizov, B., R. Dekova. Anaphora – Clause Annotation and Alignment Tool. – In: Proceedings of the Demonstrations at the 14th Conference of the European Chapter of the Association for Computational Linguistics. Gothenburg: Association for Computational Linguistics, 2014, pp. 69–72. pdf






