Първото събитие в България за популяризиране на Европейската езикова мрежа (ELG) ще се проведе на 11 февруари 2022 година. В рамките на събитието се организират два семинара:
|
Семинар 1: „Европейска езикова мрежа“ Кога: 11 февруари 2022 година от 10:00 до 11:30 часа (източноевропейско време) Къде: онлайн, в Зум и Ютюб Събитието ще се проведе на английски със симултанно субтитриране на български език. |
 Семинар 2: „Многоезиков корпус от изображения“ Кога: 11 февруари 2022 година от 12:00 до 13:00 часа (източноевропейско време) Къде: онлайн, в Зум и Ютюб Събитието ще се проведе на български език. |
| За презентациите на английски се предлага автоматичен симултанен превод и субтитриране на български език, които са осигурени от ELITR и ще бъдат достъпни на следния линк. |
| Събитието ще бъде излъчено в канала на Секцията по компютърна лингвистика в Ютюб. |
Регистрираните участници за платформата Зум ще получат детайли за включване до 10 февруари 2022 година.
Семинар 1: „Европейска езикова мрежа“
Използвате ли езикови технологии или езикови ресурси при създаването на продукти и услуги, които Вашата компания предоставя, или във Вашата научна работа? Работите ли в областта на изкуствения интелект, информационните и езиковите технологии, роботиката или компютърната обработка на езика? Търсили ли сте езикови приложения, които да интегрирате във Вашите разработки? Знаете ли достатъчно за платформите, които ги предоставят? Имате ли бизнес стратегии за това как споделянето на продукти и услуги може да допринесе за развитието на вашата компания или научна дейност?
Ако отговорът Ви на поне един от горните въпроси е положителен и искате да научите нещо повече, посетете нашия семинар „Европейска езикова мрежа“.
Кога: 11 февруари 2022 година от 10:00 до 11:30 часа
Къде: онлайн, в Зум и Ютюб
Събитието ще се проведе на английски със симултанно субтитриране на български език.
Платформата Европейска езикова мрежа е най-бързо развиващата се в момента платформа за споделяне и разпространение на езикови ресурси, програми за обработка на езика и услуги в областта на езиковите технологии. Само за няколко месеца езиковите ресурси и технологии, споделени на платформата, нараснаха на 500.
Програма
Семинарът ще засегне различни теми, включително:
- Представяне на платформата на Европейската езикова мрежа (European Language Grid)
- Демонстрация на облачната платформа на Европейската езикова мрежа
- Технологична поддръжка на многоезичието в Европа: актуално състояние
- Кратко обучение: интегриране на данни в платформата на Европейската езикова мрежа
- Добри практики от сектора на технологичните компании и потенциалните потребители на Европейската езикова мрежа
- Дискусия на заинтересованите групи
10:00 – 10:05 Светла Коева (Институт за български език) Откриване и представяне на семинара ![]()
10:05 – 10:50 Катрин Мархайнеке, Георг Рем (Немски изследователски център за изкуствен интелект) Представяне на Европейската езикова мрежа с акцент върху технологичната равнопоставеност на европейските езици; демонстрация на платформата на Европейската езикова мрежа ![]()
10:50 – 11:05 Пени Лабропулу (Институт за обработка на език и реч, Атина) Представяне на метаданни в Европейската езикова мрежа и включване на ресурси в платформата ![]()
11:05 – 11:10 Въпроси и отговори ![]()
11:10 – 11:20 Лъчезар Джаков (Skycode) Невронни мрежи в пазарна реализация на продукт за генериране на българска реч ![]()
11:20 – 11:30 Йолина Петрова (Identrics) Значението на Европейската езикова мрежа за целите на медийното разузнаване ![]()
В съвременния глобализиран свят езиковите бариери възпрепятстват междуезиковата комуникация и свободния поток на знания и информация. Езиковите технологии, особено многоезиковите, могат да помогнат за преодоляването на езиковите бариери и да внесат значителни подобрения в областта на търговията, администрацията, политиката, комуникацията и междукултурното разбирателство.
Европейската езикова мрежа разработва и внедрява мащабируема облачна платформа, осигуряваща лесен за интегриране достъп до стотици комерсиални и свободни езикови технологии за всички европейски езици, включително работещи инструменти и услуги, както и колекции от езикови данни и ресурси.
Семинар 2: „Многоезиков корпус от изображения“
Използвате ли многоезикови и многомодални (текст, звук и изображения) технологии или ресурси при създаването на продукти и услуги, които Вашата компания предоставя, или във Вашата научна работа? Работите ли в областта на изкуствения интелект, роботиката или обработката на изображения и видео? Търсили ли сте многомодални и многоезикови приложения, които да интегрирате във Вашите разработки?
Ако отговорът Ви на поне един от горните въпроси е положителен и искате да научите нещо повече, посетете нашия семинар „Многоезиков корпус от изображения“.
Кога: 11 февруари 2022 година от 12:00 до 13:00 часа
Къде: онлайн, в Зум и Ютюб
Събитието ще се проведе на български език.
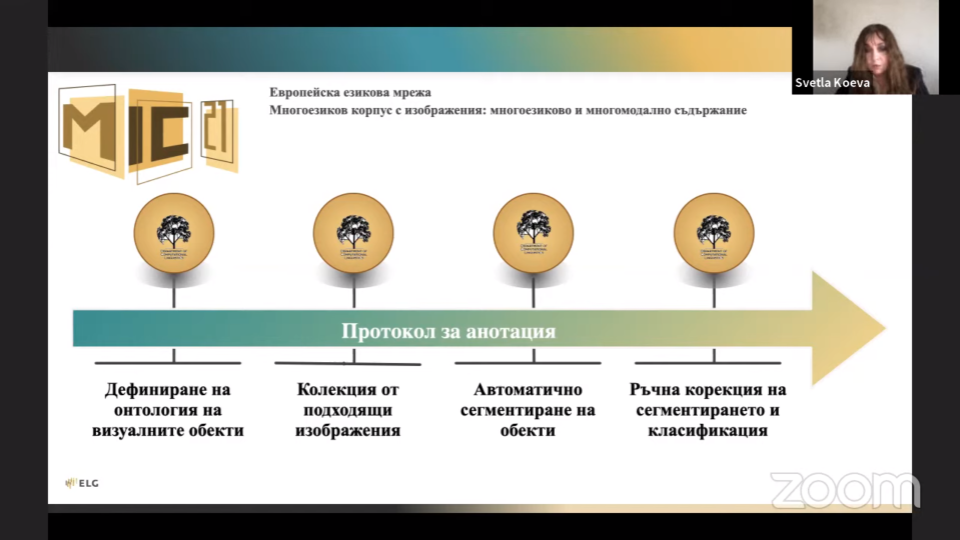
Промяната на традиционните методи за обработка на данни, предизвикана от необходимостта от обработка на многомодално съдържание, мотивира създаването на нов корпус от изображения, Многоезиковия корпус от изображения (MIC 21), който се характеризира с внимателно подбрани изображения, илюстриращи тематично свързани области и прецизна анотация за сегментиране и класификация на обектите в изображенията.
Многоезиковият корпус от изображения ще бъде достъпен за изтегляне от платформата на Европейската езикова мрежа в края на февруари 2022 г.
Програма
Семинарът ще засегне различни теми, които включват:
- Представяне на Многоезиковия корпус с изображения
- Въведение в Онтологията на визуалните обекти
- Представяне на многоезиковото описание на изображения на 24 езика
- Демонстрация на автоматично откриване и класификация на обекти
- Дискусия по различни въпроси
12:00 – 12:25 Светла Коева (Секция по компютърна лингвистика, Институт за български език – БАН) Многоезиков корпус с изображения: многоезиково и многомодално съдържание ![]()
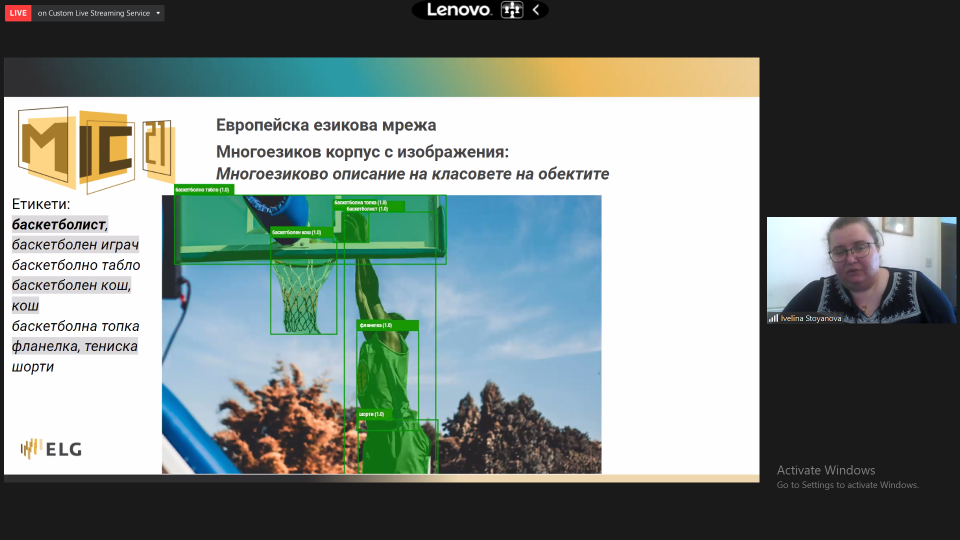
12:25 – 12:40 Ивелина Стоянова (Секция по компютърна лингвистика, Институт за български език – БАН) Многоезиково описание на класовете на обектите ![]()
12:40 – 12:55 Йордан Кралев (Технически университет, София; Секция по компютърна лингвистика, Институт за български език – БАН) Приложения и услуги, използващи Многоезиковия корпус с изображения ![]()
12:55 – 13:00 Въпроси и отговори
Многоезиковият корпус с изображения (MIC 21): (а) е голяма колекция от данни, включваща хиляди изображения и анотирани обекти, които се съдържат в тях; б) е създаден в съответствие със специално дефинираната Онтология на анотираните обекти; в) предлага паралелно описание на анотираните в изображенията обекти на 24 езика. Многоезиковият корпус с изображения има за цел да подпомогне изследванията и разработките в областта на многоезиковата и многомодалната обработка на данни.
Събитието се организира в рамките на проекта European Language Grid (2019-2022), финансиран от ЕС.
Семинарите се организират в сътрудничество с Националния център за компетентност към Европейската езикова мрежа в България (Института за български език към Българската академия на науките).
Организатор е Секцията по компютърна лингвистика към Института за български език.
Резултати от анкетите
➥ Резултати от предварителната анкета
➥ Резултати от заключителната анкета