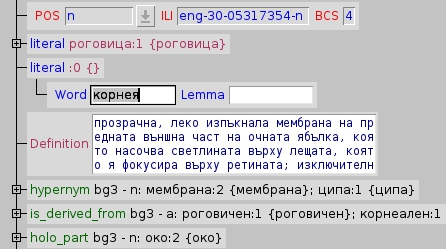
Hydra
Hydra is an OS-independent system designed for wordnet development, validation and exploration. The program enables users to browse and edit any number of monolingual wordnets at a time. The individual wordnets are synchronised, so that equivalent synonym sets, or synsets, may be viewed and explored in parallel. Fig. 1. Hydra’s Synset view with the Bulgarian WordNet and the…
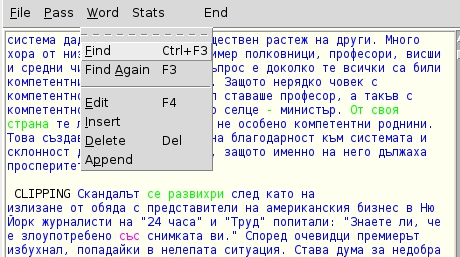
Chooser
General description Chooser is an OS independent multi-functional system for linguistic annotation adaptable to different linguistic levels and different annotation schemata. Below Chooser’s features are discussed in relation to semantic annotation. The basic annotation functionalities implemented in Chooser are: fast and easy-to-perform annotation; run-time access to detailed information for the annotation candidates through the associated wordnet senses with…

A Web-Based Infrastructure for Bulgarian Data Processing
General description The Bulgarian Language Processing Chain (developed in 2011-2012) includes the following types of text processing and linguistic annotation: • Sentence segmentation; • Tokenisation; • POS tagging and grammatical annotation; • Lemmatisation. BgTagger The Bulgarian POS tagger (BgTagger) marks up each word with the most probable Part of Speech and unambiguous morphosyntactic information among the set of…

bgMWE – a tool for MWE recognition
bgMWE is a tool for corpus processing and MWE recognition and tagging created in 2012. It is developed in Java and is thus platform independent. bgMWE comprises a set of modules which can be applied for particular NLP tasks. It is largely language independent and can work either in resource-light mode, or its performance can be boosted by employing lexical…






