General information
Title: Assessing reading literacy and comprehension of early graders in Bulgaria and Italy
Duration: 2023 – 2025
| Project leader of the Bulgarian team: prof. Svetla Koeva
Bulgarian team members: Ivelina Stoyanova, Valentina Stefanova, Tsvetana Dimitrova, Maria Todorova, Hristina Kukova |
| Project leader of the Italian team: prof. Vito Pirrelli
Italian team members: Claudia Marzi, Marcello Ferro, Andrea Nadalini, Alessandro Lento |
Main goal: To increase the level of literacy and reading abilities of primary school children through education. To contribute to the achievement of this goal, a thorough investigation focused on assessing reading literacy and comprehension in children of early school age in Bulgaria and Italy will be carried out.
Funding: the Bulgarian Academy of Sciences and the National Research Council of Italy
The project is performed in collaboration with 21st Hristo Botev Secondary School in Sofia.
Objectives
The project has the following objectives:
– To implement, and test assessment strategies for monitoring and evaluating the reading skills and the level of word comprehension of Bulgarian and Italian early graders.
– To collect reading and comprehension evidence from the two populations of children according to the same battery of tools and comparable, highly-controlled test language materials.
– To compare collected data across children from different age and social groups and with different languages (Bulgarian and Italian) and model the results.
– To document and make available evidence-based procedures, protocols, and tools for reading and word comprehension assessment.
Research method
The ICT platform with a tablet front-ent developed by the Comphys Lab at CNR ILC in Pisa will be used to provide accurate, evidence-based assessment of reading skills in early grade children. The platform, named Readlet, can automatically collect, preprocess and analyse time-aligned multimodal reading data that include: voice recording, finger sliding time, time spent to answer comprehension questions, and number of correct answers.
We will design a set of connected reading texts, containing short stories in Bulgarian and Italian, rigorously balanced and comparable in terms of their levels of readability and linguistic complexity.
Using state-of-art NLP tools, the reading texts will be annotated at different levels of linguistic analysis: from articulatory complexity (i.e. length and variety of consonant chunks) and phonological transparency, to part-of-speech tagging, lexical typicality (in terms of density and entropy of a word’s lexical neighbourhood), orthotactic probability (as a function of a word’s bigram and trigram probabilities), morphological complexity, token and type frequency, token’s position and syntactic role in a sentence.
By aligning finger tracking data with the annotated reading text and audion records, we will be in a position to relate children’s reading performance to specific linguistic factors across different grade levels, thereby gaining a better understanding of i) the basic mechanisms behind children’s reading strategy, ii) what text factors make reading more difficult, iii) and ways to enhance a reader’s strengths and overcome her weaknesses.
Meetings
Work meeting, online, 29.06.2023
On 29th June 2023 the first working meeting of the project team was held. The meeting was attended by all project members from the Institute for Bulgarian Language – prof. Svetla Koeva, assoc. prof. Tsvetana Dimitrova, assist. prof. Valentina Stefanova, assist. prof. Maria Todorova, assist. prof. Hristina Kukova (postdoctoral student), Ivelina Stoyanova, as well as by the Italian partners from the Institute for Computational Linguistics at the National Research Council of Italy – prof. Vito Pirrelli, senior researcher Claudia Marzi, researcher Marcello Ferro, researcher Andrea Nadalini, Alessandro Lento (PhD student).
All participants introduced themselves briefly and overviewed the general objectives during the first stage of the project. Prof. V. Pirrelli reviewed the work of the Italian team, presenting options for tracking the dynamics of the reading process, as well as checking reading comprehension in different age groups. The parameters and features of the science experiment implementation system (ReadLet) were discussed.
 |
 |
 |
Work meeting, Pisa, 6 – 8.11.2023
In the period 6th – 8th November 2023, prof. Svetla Koeva, assoc. prof. Tsvetana Dimitrova and Ivelina Stoyanova made a working visit to the Institute for Computational Linguistics A. Zampoli in Pisa, Italy. A series of working meetings were held with the Italian team – prof. Vito Pirrelli, senior researcher Claudia Marzi, researchers Marcello Ferro and Andrea Nadalini, and Alessandro Lento (PhD student). During the meetings, a general presentation of the project was made by the Italian team and a discussion was held on the main objectives, the ReadLet reading skills assessment application developed and used by the Italian team, as well as the main features and problems in data collection. Dr. Tsvetana Dimitrova presented a set of tasks for online experiments in the form of language games developed by the Bulgarian team, as well as a summary and analysis of the obtained results. The results of the Italian team’s research were also presented (comparative studies on children with typical language development and children with autism spectrum disorders, children in monolingual and bilingual environments, adults). Attention was paid to the advantages of the system and the method of finger tracking compared to other methods of evaluating reading skills (e.g., eye tracking), as well as the parameters of the campaign that is planned to be carried out in Bulgaria. The technical approaches to ensure the comparability of the Italian and the Bulgarian texts were discussed, as well as the possible analytical tools to be applied to process the results.
 |
 |
 |
Work meeting, Sofia, 5 – 6.12.2023 г.
On 5th and 6th December 2023, prof. Vito Pirrelli and researcher Andrea Nadalini visited the Institute for Bulgarian Language Prof. Lyubomir Andreychin, where they met the Bulgarian team: prof. Svetla Koeva, assist. prof. Maria Todorova, assist. prof. Hristina Kukova and assist. prof. Valentina Stefanova.
During the series of meetings prof. Pirrelli and researcher Nadalini explained the work with the ReadLet application, as well as the principles for conducting the experiments, according to their practice in Italy. Andrea Nadalini talked about the methods of data collection for the experiments, as well as the subsequent analysis and statistical processing. A meeting was held with Mrs. Maya Angelova, head-teacher of the 21. Hristo Botev Secondary School in Sofia, in order to discuss cooperation between the Bulgarian team and the school. The working schedule for the coming months, the means of communication and the expected results were outlined. On 6th December prof. Vito Pirrelli gave a lecture to a wider audience at the Bulgarian Academy of Sciences in order to promote the objectives and the expected results of the project.
 |
 |
 |
2024
29/05/2024, online
Participants: Svetla Koeva, Tsvetana Dimitrova, Valentina Stefanova, Hristina Kukova, Maria Todorova, Ivelina Stoyanova (Institute for Bulgarian Language at the Bulgarian Academy of Sciences); Vito Pirrlelli, Marcello Ferro, Andrea Nadalini, Alesandro Lento (Institute of Computational Linguistics “Antonio Zampoli” at the National Center for Scientific Research, Pisa, Italy)
During the meeting, Marcello Ferro presented an analysis of the processed data in the MATLAB system. It was explained that the analysis can be focused on different segments of the read text – episode, paragraph, sentence, line, token, etc. The analysis can include time, duration of finger hold, number of occurrences of the word, word length, word frequency, number of syllables, distance from the beginning or end of the line, what part of the word was traced before it was read, number of letters read per second, number of syllables read per second, etc. The issue of automatic processing of audio recordings into text (text-to-speech), as well as automatic division of words into individual syllables, was discussed.
 |
 |
 |
09/09/2024 – 11/09/2024, Sofia
Participants: Svetla Koeva, Tsvetana Dimitrova, Valentina Stefanova, Hristina Kukova, Maria Todorova, Ivelina Stoyanova (Institute for Bulgarian Language at the Bulgarian Academy of Sciences); Vito Pirrlelli, Andrea Nadalini (Institute of Computational Linguistics “Antonio Zampoli” at the National Center for Scientific Research, Pisa, Italy)
The Italian team members made their work visit in connection with their participation in the Sixth International Conference on Computational Linguistics in Bulgaria. Vito Pirrelli delivered a plenary talk on the topic, while Andrea Nadalini presented the paper, co-authored by all project participants which outlined the main results of the work done in 2024. Several workshops were held where future directions of research were discussed, incl.: the role of n-gram frequency on the speed of words’ finger-trace; the correlation between finger tracing time and articulation time in reading aloud and evaluating the implicit prosody hypothesis (Breen, 2014), i.e., the hypothesis that when reading silently, readers activate a prosodic representation that is similar to that in reading aloud.
 |
 |
 |
 |
 |
 |
03/12/2024 (online)
Participants: Svetla Koeva, Tsvetana Dimitrova, Valentina Stefanova, Hristina Kukova, Maria Todorova, Ivelina Stoyanova (Institute for Bulgarian Language at the Bulgarian Academy of Sciences), Vito Pirrlelli, Andrea Nadalini, Marcello Ferro, Claudia Marzi (Institute of Computational Linguistics “Antonio Zampoli” at the National Center for Scientific Research, Pisa, Italy).
In this workshop, we discussed the results of our work and outlined the main steps for the work in 2025, incl. the prospects of collecting new data to be compared with the one collected so far and to attest for the progress in reading skills, taking into account the linguistic and extralinguistic factors. Marcello Ferro demonstrated possible directions of comparative statistical analysis, both within one language and interlingually. The importance of future results for teachers and parents was emphasized, with a focus on anonymity and general conclusions (without a focus on the specific pupil).
 |
 |
 |
 |
 |
 |
Results
In 2023 the following activities were carried out:
- Adaptation and customisation of existing protocols and software products to create language tasks and collect and store data on reading assessments of primary school children for both languages.
The ReadLet platform developed by the Italian team is used to automatically collect, pre-process and analyse synchronised multimodal reading data, which includes: voice recording, finger sliding time recording, response time to comprehension questions on the text, and the number of correct answers. Bulgarian texts were integrated into the platform to perform data collection on Bulgarian, and initial tests were carried out. The platform was localised for Bulgarian.
- Assessment of data protection and privacy requirements.
The European and Bulgarian legislation on personal data protection was studied and a package of documents necessary for conducting the experiment at school was prepared – an invitation to cooperate (with professionals and schools), an invitation to participate, a sample letter of consent from a parent or guardian.
- Design and development of comparable language materials and language tasks suitable for assessing reading skills and levels of information decoding and content comprehension during reading for primary school children for both languages.
The texts were created specifically for the intended research purposes in Italian. The texts have a specific structure: each of them consists of five episodes, and the level of difficulty of the text increases with each subsequent episode. After each episode, two questions are asked about the text with four possible answers, from which the correct one can be chosen.
The texts have been translated into Bulgarian. The translation was further adapted to match the intended complexity (sentence length calculated as the average number of words in a sentence and word length calculated as the average number of letters in a word), lexical characteristics (percentage of unique words in the text vs. selected for age reference list; distribution between ‘core vocabulary’, words with high frequency of use and words with relatively lower frequency referring to everyday objects or actions) and morpho-syntactic features (depth of the syntactic tree or longest path from the root of the tree to the leaves / words; the average depth of the syntactic tree of subordinate clauses; the word order of subordinate clauses; the length of dependent links, etc.).
- Design and development of controlled comparable language materials and language tasks suitable for assessing the level of knowledge of core vocabulary and its appropriate use by primary school children for both languages.
The experiments to assess the understanding of the meaning of a selected set of words were conducted in a partially controlled manner during the Sofia Science Festival (11-14.05.2023) and the European Day of Languages (30.09.2023) in Sofia with 73 respondents. The work on the creation of the tasks and the conduct of the experiments, as well as the analysis of the obtained results, were presented to the Italian team during a meetingp in Pisa (6.11.2023).
- Defining target groups and agreeing data collection with school authorities and parents.
The experiment in Italy was conducted with 120 students from 2nd to 5th grade. In Bulgaria, cooperation was established with the 21st Hristo Botev Secondary School in Sofia to conduct the experiment with 80 students from 2nd to 5th grade. Consent data from parents or guardians is being processed.
In 2024 the following activities were carried out:
- Collection of data to assess reading literacy of pupils from the target groups (2nd, 3rd, 4th и 5th grade) in both languages
Between 19 and 29 February 2024, we organised and conducted reading sessions to collect anonymised audio and haptic data to assess the reading literacy of pupils (2nd, 3rd, 4th and 5th grade).
72 pupils from 21. Hristo Botev Secondary School in Sofia participated in the experiment: 21 second-graders, 18 third-graders, 14 fourth-graders, and 18 fifth-graders. 21 second-graders, 18 third-graders, 14 fourth-graders and 18 fifth-graders. The second-graders read only the first two episodes of each story, the third-graders read the first three episodes and so on. The pupils have to read one story aloud and one silently, tracking the words with their fingers.
In order to collect data on the reading literacy and reading comprehension of the different age groups, the texts were organised according to a specific structure: Each text consists of five episodes of increasing difficulty. - Collection of data to assess lexical knowledge of pupils from the target groups through
associative and thematic language tasks
In the tests constructed for the experiment, two questions were asked after each episode (with four possible answers and one correct answer among them). The primary aim is not to test comprehension and analytical thinking, but to see whether the students have actually read silently and not just traced the words with their fingers. Nevertheless, the questions require lexical knowledge and the incorrect answers reflect possible incorrect associations. Therefore, the collected answers can be used to assess lexical knowledge.
A total of 40 questions (two to five episodes of four stories) were asked: 21 second-graders, 18 third-graders, 14 fourth-graders and 18 fifth-graders. The number of questions answered by the pupils was 84 for the second grade, 108 for the third grade, 112 for the fourth grade and 180 for the fifth grade. - Preliminary analysis of the data (for each language and across languages).
The Bulgarian translations of the Italian texts were preprocessed using the Bulgarian natural language processing pipeline, which combines several natural language processing tools, including a sentence splitter, a tokeniser, a part-of-speech (POS) tagger, a lemmatiser, a noun phrase (NP) extractor, a named entity recogniser and a stop word recogniser, and an automatic analysis of universal dependencies. The lexical features of the Bulgarian texts were controlled in two ways: (i) by comparing the vocabulary used in each translated text with the general Bulgarian lexis and (b) by calculating the type/token ratio, i.e. the ratio between the number of lexical types (i.e. lemmas) and the number of tokens (i.e. word forms) actually occurring in the texts. The comparison of word and sentence lengths in Bulgarian and Italian texts shows that the relatively small number of words in a sentence is kept in Bulgarian, as is the tendency to use relatively short words with a relatively simple morphological structure. The slightly longer average word length in the Bulgarian texts is due to the morphological structure of nouns, adjectives and some pronouns and numerals with definite articles. Similarly, the relatively lower average word count in Bulgarian can generally be explained by the fact that the Italian determiners are independent words.
The resulting dataset was analysed with the statistical software R using generalised additive models (GAMs) with the package gamm4, version 0.2-6.
To understand the factors influencing reading speed with finger tracking, we entered token tracking time (i.e., the time it takes the finger to underline a single word token) as the dependent variable in two GAM models with the independent variables: grade level (from 2nd to 5th grade) and reading type (loud vs. silently) as categorical factors and word length or word frequency as numerical factors. Finally, to account for individual variability in the sample and to control for the effects of lexical variability in the texts, individual participants and individual words were entered as random effects.
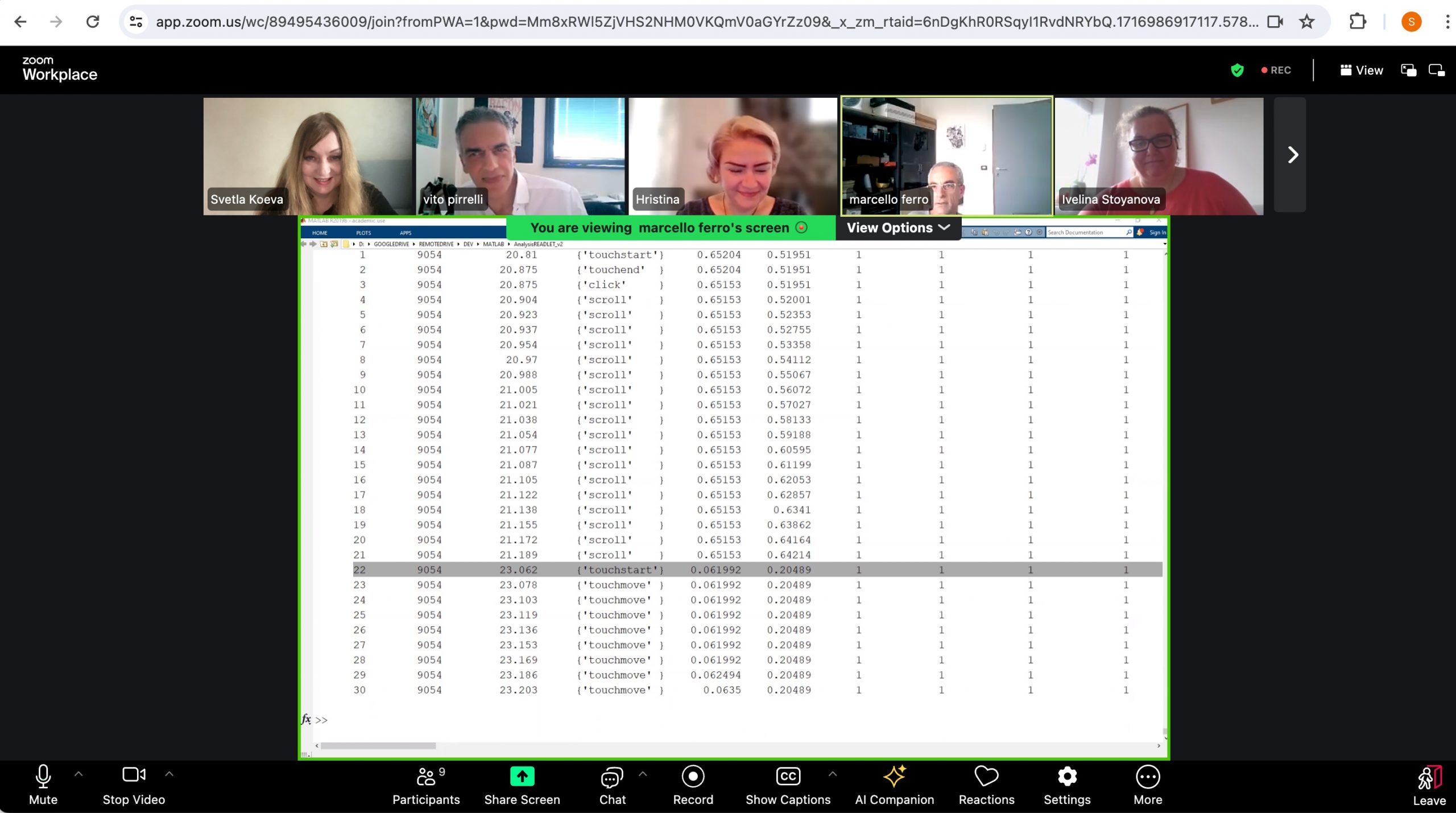
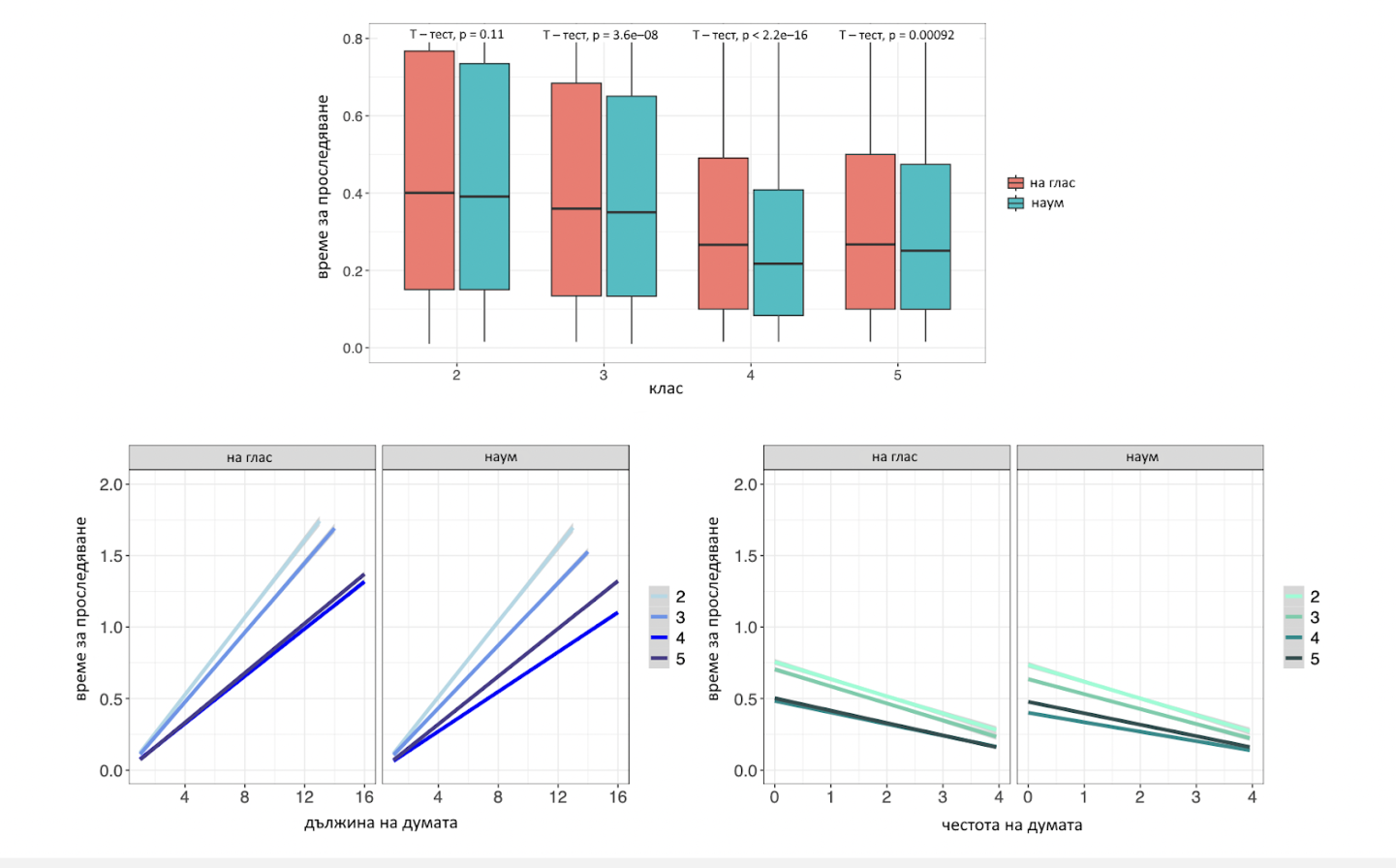
The results show that finger tracking times are significantly shorter for silent reading than for reading aloud in grades 3, 4 and 5 (p-value < 0.001). In addition, there is a decreasing trend in finger tracking times with increasing grades level (p-value < 2e − 16), with a plateau between grades 4 and 5 for both reading conditions. We hypothesise that this levelling effect is due to the higher complexity of the additional episodes read by fifth graders.
Figure 1. Statistical results and correlations
The effects of word length (lower left panel) and word frequency (lower right panel) on tracking times show a significant interaction with grade level, with early grade children (2nd and 3rd grade) being more influenced by both word length and word frequency than older children (4th and 5th grade) (p-values < 2e − 16). The effect, which was also observed in the reading data collected using the same finger-tracking technology, shows that the orthographic lexicon of Bulgarian fourth and fifth graders not only contains more words than the orthographic lexicon of second and third graders, but also significantly longer and less frequent words. As a result, longer words (left panel) and less frequent words (right panel) slow down the speed of finger movement less in Bulgarian fourth and fifth graders than in Bulgarian second and third graders. Results also show a significant interaction between word length or frequency and the reading conditions, with finger-tracking reading being significantly more influenced by both word length and word frequency in the reading aloud condition than in the silent reading condition (p-values < 2e − 16). This not only shows that longer and less frequent words are more difficult to process and understand. Their articulation also requires more time for planning and execution. This is further indirect evidence of the strong correlation between finger-tracking times and articulation times.
- Preparation, organisation and implementation of a thematic course to improve the qualification of pedagogical professionals and to acquire qualification points
On 16 and 17 March 2024, a thematic course was organised to improve the qualification of pedagogical professionals and to acquire qualification points (in accordance with Regulation No. 15/22.07.2019 of the Minister of Education and Science (for Bulgarian language teachers in primary and lower secondary education) entitled Assessment of reading literacy and reading comprehension of early graders.
The lecturers were the members of the Bulgarian project team: Svetla Koeva, Tsvetana Dimitrova, Valentina Stefanova, Hristina Kukova, Maria Todorova and Ivelina Stoyanova.
Presentations
During the Eighth Forum on Research Approaches in Bulgarian Language Education, which took place on 1st November 2023 in the Acad. Alexander Teodorov-Balan Hall at the Institute for Bulgarian Language in Sofia, the project Assessing reading literacy and comprehension of early graders in Bulgaria and Italy was presented to scientists, university lecturers, teachers and Bulgarian language experts. The paper was submitted for anonymous review to the Bulgarian Language Journal.
 |
 |
 |
During the International Conference Bulgarian Linguistic Studies, held on 23rd and 24th November 2023 at Sofia University, the Bulgarian team introduced the objectives and the tasks of the project, as well as the experiments planned to assess reading skills of children from the project’s target group. The paper is expected to be published next year in the Conference proceedings.
 |
 |
 |
On 6th December 2023, in the Ivan Evstratiev Geshov Hall (207) at the Bulgarian Academy of Sciences, prof. Vito Pirrelli gave a lecture on the topic Assessing reading literacy with the finger-voice span. The lecture took place amid increased interest from the academic community – representatives of the Bulgarian Academy of Sciences, university lecturers, students and teachers, as well as experts from the Ministry of Education and Science were present.
 |
 |
 |
2024
Alessandro Lento, Andrea Nadalini, Marcello Ferro, Claudia Marzi, Vito Pirrelli, Tsvetana Dimitrova, Hristina Kukova, Valentina Stefanova, Maria Todorova, Svetla Koeva: Assessing Reading Literacy of Bulgarian Pupils with Finger–tracking. Sixth International Conference on Computational Linguistics in Bulgaria (CLIB 2024). ![]()
Vito Pirrelli. (NRC, Institute for Computational Linguistics, Pisa, Italy): Written Text Processing and the Adaptive Reading Hypothesis. Sixth International Conference on Computational Linguistics in Bulgaria (CLIB 2024). ![]()

Svetla Koeva (Institute for Bulgarian Language at the Bulgarian Academy of Sciences). Приложение на езиковите технологии за оценка на усвояването на езика (Applying language technologies to assess language acquisition). Contacts of Languages and Cultures 2024 Modern resources in teaching Bulgarian as a foreign/second language. 17-19 September 2024. Veliko Tarnovo.

Hristina Kukova (Institute for Bulgarian Language at the Bulgarian Academy of Sciences), Gergana Budinova (21. Hristo Botev Secondary School, Sofia). Изследване на уменията за четене – среща между наука и образование (Assessing reading skils – to join science and education). 9th Forum on Research Approaches in Bulgarian Language Teaching, 01/11/2024, Sofia. ![]()
 |
 |
 |
Maria Todorova (Institute for Bulgarian Language at the Bulgarian Academy of Sciences): a guest lecture on Theoretical Analyses and Natural Language Processing for and via Language Learning and Teaching within a series of webinars I teach with technology, organised by the British Association of Applied Linguistics BAAL Language Learning and Teaching SIG on 13/11/2024

Publications
2023
Светла Коева, Валентина Стефанова, Ивелина Стоянова, Мария Тодорова. Оценка на уменията за четене в начална училищна възраст. – Български език. Приета за печат. (Svetla Koeva, Valentina Stefanova, Ivelina Stoyanova, Maria Todorova. Assessment of reading skills in primary school age. – Bulgarian Language. Accepted for publication.)
Vito Pirelli, Svetla Koeva. Developing Materials for Assessing Reading Literacy and Comprehension of early Graders in Bulgaria and Italy. – Foreign Language Education. Accepted for publication.
2024
Alessandro Lento, Andrea Nadalini, Marcello Ferro, Claudia Marzi, Vito Pirrelli, Tsvetana Dimitrova, Hristina Kukova, Valentina Stefanova, Maria Todorova, and Svetla Koeva. 2024. Assessing Reading Literacy of Bulgarian Pupils with Finger–tracking. In Proceedings of the Sixth International Conference on Computational Linguistics in Bulgaria (CLIB 2024), pages 140–149, Sofia, Bulgaria. Department of Computational Linguistics, Institute for Bulgarian Language, Bulgarian Academy of Sciences. ISSN: 2367-5675. DOI: https://doi.org/10.47810/CLIB.24.14 (ACL, Scopus)
Vito Pirrelli, Svetla Koeva. Developing Materials for Assessing Reading Literacy and Comprehension of еarly Graders in Bulgaria and Italy. – Чуждоезиково обучение, 2024, кн. 1. ISSN: 0205–1834 (Print), 1314–8508 (Online). DOI: https://doi.org/10.53656/for2024-01-03 (PDF)
Светла Коева, Христина Кукова, Цветана Димитрова, Валентина Стефанова. Оценка на уменията за четене и разбиране в начална училищна възраст. Сборник от Втората международна научна конференция „Българистични езиковедски четения“, посветена на 100-годишнината от рождението на проф. Мирослав Янакиев, 23 – 24 ноември 2023 г., Софийски университет „Св. Климент Охридски“. ISBN 978-619-7785-06-7 (твърда подвързия), ISBN 978-619-7785-07-4 (submitted)
Светла Коева. Приложение на езиковите технологии за оценка на усвояването на езика. Сборник с доклади от конференцията Контакт на езици и култури 2024 Съвременни ресурси в обучението по български език като чужд/втори. 17-19 септември 2024. Велико Търново. София: Издателство на Софийския университет. (submitted)






