Обща информация
Срок: 2023 – 2025
| Ръководител на проекта на българския екип: проф. Светла Коева
Участници от българския екип: д-р Ивелина Стоянова, гл. ас. д-р Валентина Стефанова, доц. д-р Цветана Димитрова, гл. ас. д-р Мария Тодорова, гл. ас. д-р Христина Кукова |
| Ръководител на проекта на италианския екип: проф. Вито Пирели
Участници от италианския екип: ст. изсл. Клаудия Марци, изсл. Марчело Феро, изсл. Андреа Надалини, Алесандро Ленто (докторант) |
Основна цел на проекта: Да се повиши нивото на грамотност и способностите за четене и разбиране на децата в начален етап на обучение. За постигането на тази цел ще се проведе задълбочено проучване, фокусирано върху оценка на уменията за четене и способностите за разбиране на съдържанието на текста при деца в начална училищна възраст в България и в Италия.
Финансиране: Българската академия на науките и Националния съвет за научни изследвания в Италия
Проектът се осъществява в сътрудничество с 21. средно училище „Христо Ботев“ в гр. София.
Задачи
Проектът си поставя следните задачи:
– Да се разработят и тестват стратегии за наблюдение и оценка на уменията за четене и разбиране при ученици в началните класове в България и в Италия.
– Да се съберат данни за нивото на четене и разбиране на децата в двете страни съгласно споделен набор от инструменти и съотносими, строго контролирани тестови материали.
– Да се направи съпоставка на събраната информация за нивото на уменията за четене и разбиране от различни възрастови и социални групи, владеещи различни езици (български и италиански).
– Да се документират и публикуват процедури, протоколи и инструменти, свързани с уменията за четене и разбиране, базирани на емпиричните наблюдения.
Метод на изследване
Ще бъде използвана платформа за автоматичен анализ и оценка на уменията за четене с помощта на таблет (от Института по компютърна лингвистика в Пиза).
Платформата предоставя точна оценка на уменията за четене, основана на емпиричен материал.
Платформата ще се използва за автоматично събиране, предварителна обработка и анализ на синхронизирани многомодални данни за четене, които включват: гласов запис при четене; запис на времето на плъзгане на пръста под текста при четене; времето за отговор на въпроси, проверяващи разбирането на текста; и броя правилни отговори.
Ще бъдат съставени подходящи текстове за четене – разкази на български и италиански, балансирани и сравними по отношение на нивото на четивност и езиковата сложност. С помощта на съвременните инструменти за обработка на естествен език текстовете ще бъдат анотирани на различни езикови равнища: артикулационна сложност (дължина и разнообразие на отделните думи при изговор), маркиране на частите на речта, лексикална типичност (от гледна точка на употребата и разпространението на думите), ортотактична вероятност (възможността за образуване на биграми и триграми с дадена дума), морфологична сложност, честота на срещане на основните форми и на словоформите, позиция на думата и синтактична ѝ роля в изречението.
Чрез съотнасяне на данните за траекторията, описана с пръста, аудиоинформацията и анотирания текст за четене ще бъде направен анализ на специфични езикови фактори за уменията за четене на деца от различна възраст, като по този начин ще се постигне по-добро разбиране за: а) основните механизми при стратегиите за четене на децата; б) кои характеристики на текста затрудняват четенето; в) възможностите за подобряване на уменията за четене и преодоляване на някои дефицити и трудности.
Работни срещи
2023
Работна среща, онлайн, 29.06.2023 г.
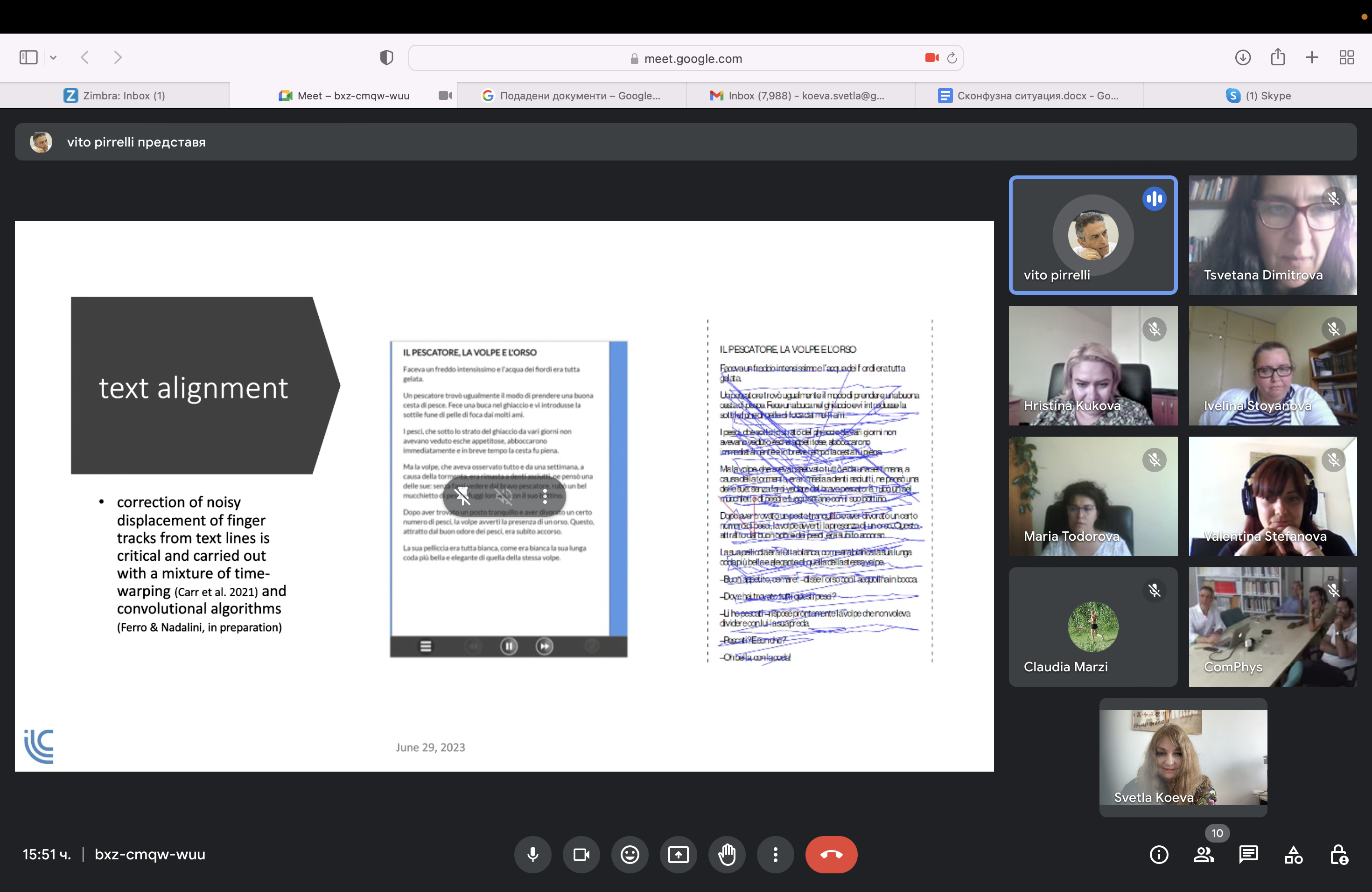
На 29 юни 2023 г. се проведе първа работна среща на екипа по проекта „Оценка на уменията за четене и разбиране в начална училищна възраст в България и Италия“ с продължителност 2023 – 2025 г. На срещата присъстваха всички участници в проекта както от страна на Института за български език „Проф. Л. Андрейчин“, БАН – проф. Светла Коева, доц. Цветана Димитрова, гл. ас. Валентина Стефанова, гл. ас. Мария Тодорова, гл. ас. Христина Кукова (постдокторант), д-р Ивелина Стоянова, така и от страна на италианските партньори от Института за компютърна лингвистика „А. Замполи“ към Националния съвет за научни изследвания на Италия – проф. Вито Пирели, ст. изсл. Клаудия Марци, изсл. Марчело Феро, изсл. Андреа Надалини, Алесандро Ленто (докторант).
Всички участници се представиха накратко и уточниха общите цели в първия етап от проекта. Проф. В. Пирели направи обзор на работата на италианския екип, като представи варианти на проследяването на динамиката на процеса на четене, както и проверката на четене с разбиране при различни възрастови групи. Бяха обсъдени параметрите и особеностите на системата за изпълнение на научния експеримент (ReadLet).
 |
 |
 |
Работна среща, Пиза, 6 – 8.11.2023 г.
В периода 6 – 8 ноември 2023 г. проф. д-р Светла Коева, доц. д-р Цветана Димитрова и д-р Ивелина Стоянова осъществиха работно посещение в Института за компютърна лингвистика „А. Замполи“ в Пиза, Италия. Бяха проведени поредица от работни срещи с проф. Вито Пирели, ст. изсл. Клаудиа Марци, ст. изсл. Марчело Феро, изсл. Андреа Надалини и Алесандро Ленто (докторант). По време на работните срещи беше направено общо представяне на проекта от италианския екип и проведена дискусия за основните цели, системата за проверка на уменията за четене ReadLet, разработена и използвана от италианския екип, и основни особености и проблеми при събирането на данните. Д-р Цветана Димитрова представи задачи за онлайн експерименти под формата на езикови игри, разработени от българския екип, както и обобщение и анализ на получените резултати. Бяха представени резултатите от научните изследвания на италианския екип (сравнителни изследвания между деца с типично езиково развитие и деца с нарушения от аутистичния спектър, деца в едноезикова и в билингвална среда, възрастни). Беше отделено внимание и на предимствата на системата и на метода за следене на текст с пръст при четене (finger tracking) в сравнение с други методи за проверка на уменията за четене (следене на погледа – eye tracking), както и параметрите за провеждане на кампанията в България за проверка на четивната грамотност. Бяха дискутирани техническите подходи за осигуряване на сравнимост на текстовете на италиански и на български, както и възможните инструменти за анализ, които ще бъдат приложени.
 |
 |
 |
Работна среща, София, 5 – 6.12.2023 г.
На 5 и 6 декември 2023 г. проф. Вито Пирели и изсл. Андреа Надалини бяха на работно посещение в Института за български език „Проф. Любомир Андрейчин“, където се срещнаха с екипа на проекта от българска страна: проф. д-р Светла Коева, гл. ас. д-р Мария Тодорова, гл. ас. д-р Христина Кукова и гл. ас. д-р Валентина Стефанова.
По време на поредицата от работни срещи проф. Пирели и изсл. Надалини разясниха работата с приложението ReadLet, както и принципите за провеждане на експериментите, съобразно тяхната практика в Италия. Изсл. Надалини разказа за начините на събиране на данните за експериментите, както и за последващия анализ и статистическа обработка. Беше проведена среща с г-жа Мая Ангелов, директор на 21. средно училище в град София, с цел обсъждане на сътрудничество на българския екип и екип от училището. Беше очертан планът за работа през следващите месеци, средствата за комуникация и очакваните резултати. На 6 декември проф. Вито Пирели изнесе лекция пред по-широк кръг от слушатели в Бъгарската академия на науките с цел популяризиране на целите и очакваните резултати от проекта.
 |
 |
 |
2024
Работна среща, онлайн, 29.05.2024 г.
Участници: проф. Светла Коева, доц. Цветана Димитрова, гл. ас. Валентина Стефанова, гл. ас. Мария Тодорова, гл. ас. Христина Кукова (постдокторант), д-р Ивелина Стоянова (Институт за български език „Проф. Л. Андрейчин“, БАН), проф. Вито Пирели, изсл. Марчело Феро, изсл. Андреа Надалини, Алесандро Ленто (докторант) (Институт за компютърна лингвистика „А. Замполи“ към Националния съвет за научни изследвания на Италия)
По време на срещата изсл. Марчело Феро представи анализ на обработените данни в системата MATLAB. Беше разяснено, че анализът може да бъде фокусиран върху различни сегменти от прочетения текст – епизод, абзац, изречение, ред, токън и т.н. Анализът може да включва време, продължителност на задържане на пръста, брой срещания на думата, дължина на думата, честота на думата, брой срички, отстояние от началото или от края на реда, каква част от думата е била проследена, преди да бъде прочетена, брой прочетени букви в секунда, брой прочетени срички в секунда и др. Беше дискутиран въпросът за автоматичната обработка на аудио записите в текст (text-to-speech), както и автоматичното разделяне на думите на отделни срички.
 |
 |
 |
Работна среща, гр. София, 09.09.2024 – 11.09.2024 г.
Участници: проф. Светла Коева, гл. ас. д-р Цветана Димитрова; гл. ас. д-р Валентина Стефанова; гл. ас. д-р Христина Кукова; гл. ас. д-р Мария Тодорова; гл. ас. д-р Ивелина Стоянова (Институт за български език „Проф. Л. Андрейчин“, БАН), проф. Вито Пирели, изсл. Андреа Надалини (Институт за компютърна лингвистика „А. Замполи“ към Националния съвет за научни изследвания на Италия)
Посещението на италианските колеги беше във връзка с участието им на Шестата международна конференция Computational linguistics in Bulgaria. Проф. Вито Пирели изнесе пленарен доклад на тема, а изсл. Андреа Надалини изнесе доклад на тема, чиито автори са всички участници в проекта от двете държави и който представя основните резултати от изследванията през 2024 година. По време на престоя на италианските колеги бяха проведени няколко работни срещи, в които се дискутираха бъдещите насоки на изследвания, а именно: изследване на ролята на честотата на n-грамите върху скоростта на проследяване на думите с пръст; изследване на корелацията между времето за проследяване с пръст и времето на артикулация при четене на глас и оценка на хипотезата за имплицитната прозодия (Breen, 2014), т.е. на идеята, че при четене наум читателите активират прозодично представяне, което е подобно на това, при произнасяне на глас.
 |
 |
 |
 |
 |
 |
Работна среща, онлайн, 03.12.2024 г.
Участници: проф. Светла Коева (Институт за български език „Проф. Л. Андрейчин“, БАН), проф. Вито Пирели, изсл. Андреа Надалини (Институт за компютърна лингвистика „А. Замполи“ към Националния съвет за научни изследвания на Италия), изсл. Марчело Феро, ст. изсл. Клаудия Марци; гл. ас. д-р Цветана Димитрова; гл. ас. д-р Валентина Стефанова; гл. ас. д-р Христина Кукова; гл. ас. д-р Ивелина Стоянова (Институт за български език „Проф. Л. Андрейчин“, БАН).
Беше проведена работна среща по проекта, на която бяха обсъдени резултатите от 2024 година и набелязани основните етапи от работата през 2025 година. На сериозна обсъждане беше подложена възможността да се съберат нови данни, които да бъдат съпоставими със събраните досега и да показват развитието на уменията за четене с отчитане на лингвистичните и екстралингвистичните фактори, валидни при провеждането на експеримента. Изсл. Марчело Феро демонстрира възможни направления на съпоставителния статистически анализ, както в рамките на един език, така и междуезиково. Беше подчертана важността на бъдещите резултати за учителите и родителите, като сепциално се подчерта пълната анонимност ан даннитте и изводите по същество, а не за конкретния ученик.
 |
 |
 |
 |
 |
 |
2025
Работна среща, онлайн, 18.07.2025 г.
Участници: проф. Светла Коева (Институт за български език „Проф. Л. Андрейчин“, БАН), проф. Вито Пирели, ст. изсл. Клаудия Марци, изсл. Марчело Феро (Институт за компютърна лингвистика „А. Замполи“ към Националния съвет за научни изследвания на Италия)
По време на срещата проф. Светла Коева разказа за работата на българския екип във връзка с провеждането на втората кампания за събиране на звукови и тактилни данни, осъществена през месец февруари 2025 година; изсл. Марчело Феро представи анализа на обработените данни за български език досега; ст. изсл. Клаудия Марци сподели своите наблюдения за наличието на общи модели в данните за български и италиански. Беше решено анализът на данните да продължи и през месец септември да бъде обобщен и представен в научна публикация за престижно списание. Проф. Вито Пирели сподели, че преобразуването на реч в текст за италиански е с висока прецизност и са направени експерименти за български език. Предложи следващите етапи от общата работа да бъдат в тази насока и за цялостното сравнение между двата езика.
 |
 |
 |
Работна среща, гр. Пиза, Италия, 04.11.2025 г.
Участници: гл. ас. д-р Христина Кукова, гл. ас. д-р Мария Тодорова, гл. ас. д-р Валентина Стефанова (Институт за български език „Проф. Л. Андрейчин“, БАН); проф. Вито Пирели, изсл. Андреа Надалини, изсл. Марчело Феро, ст. изсл. Клаудия Марци (Институт за компютърна лингвистика „А. Замполи“ към Националния съвет за научни изследвания на Италия); проф. д-р Светла Коева (Институт за български език „Проф. Л. Андрейчин“, БАН)
Програмата на посещението включваше две работни сесии: сутрешна и следобедна.
По време на сутрешната сесия бяха обсъдени въпроси, свързани с постигнатите до момента резултати и възможностите за анализ на събраните данни от проведените сесии с ученици в България и Италия. В разговора бяха обсъдени различни възможности за бъдеща обработка на автоматично извлечените данни за български. Една от тях е отбелязване на грешки и анализ чрез ръчна проверка и оценка на автоматично генерирания синтезиран говор (text-to-speech). Беше обсъдена и възможността за организиране на уъркшоп с учители и заинтересовани учени, по време на който да бъдат представени резултатите, които данните предоставят, както и да се формулират препоръки, на базата на изнесените данни, които да бъдат в помощ за индивидуалните потребности на учениците и образователните системи. Бяха предложени различни варианти за анализ на данни, представящи способностите на отделен участник (ученик), както и неговия напредък или прояви на забавяне при четене.
По време на следобедната сесия д-р В. Стефанова направи презентация на тема „Assessment of Reading Skills with Finger Tracking: Some Observations and Recommendations for Bulgarian“. Презентацията включваше изследване на данни за четири групи от думи с 5, 6, 7 или 8 букви. Д-р Хр. Кукова и д-р М. Тодорова обясниха някои изключения от представените данни за продължителността на четене на глас и наум, които се дължат на морфологични особености на думите – например наличие на представки, сложност на корена и част на речта.
Анализът на данните беше осъществен в две стъпки:
• Сравнение на средната стойност на четене на глас и четене наум за всяка част на речта в определените групи, наблюдения и анализ;
• Сравнение на средната стойност на четене на глас и четене наум за думи с префикс в определените групи, наблюдения и анализ.
След презентацията бяха дискутирани лингвистични маркери спрямо изведените данни, възможна категоризация на грешки при четенето.
От италианска страна д-р Клаудия Марци представи за обсъждане отделни въпроси от съвместната статия на българския и италианския екип, която е подадена в списание Languages.
 |
 |
 |
Публично представяне на резултатите от проекта, София, 9.12.2025 г.
Участници: проф. д-р Светла Коева, доц. д-р Цветана Димитрова, гл. ас. д-р Христина Кукова, гл. ас. д-р Мария Тодорова, гл. ас. д-р Валентина Стефанова, гл. ас. д-р Ивелина Стоянова (Институт за български език „Проф. Л. Андрейчин“, БАН); проф. д-р Татяна Ангелова, доц. д-р Венера Матеева-Байчева (Софийски университет „Св. Кл. Охридски“); членове на различни секции на Института за български език „Проф. Л. Андрейчин“, БАН.
Програмата на представянето включваше: представяне на проекта (проф. д-р Светла Коева); представяне на рецензия и въпроси (проф. д-р Татяна Ангелова), представяне на рецензия и въпроси (доц. д-р Венера Матеева-Байчева); дискусия.
 |
 |
 |
 |
 |
 |
 |
 |
 |
Резултати
През 2023 година бяха изпълнени следните дейности:
- Адаптиране и персонализиране на съществуващите протоколи и софтуерни продукти за създаване на езикови задачи и събиране и съхраняване на поведенчески данни при четене на ученици в началните класове за двата езика.Платформата Рийдлет (ReadLet), разработена от италианския екип, се използва за автоматично събиране, предварителна обработка и анализ на синхронизирани мултимодални данни за четене, които включват: гласов запис, запис на времето на плъзгане на пръста, времето за отговор на въпроси, проверяващи разбирането на текста, и броя правилни отговори. Беше извършена интеграция в платформата на български текстове, предназначени за събиране на данни, и бяха проведени първоначални тестове. Платформата беше локализирана за български език.
- Оценка на нуждата от защита на данните и поверителността.Беше проучено европейското и българското законодателство за защита на личните данни и беше изготвен пакет от документи, необходими за провеждането на експеримента в училище – покана за сътрудничество, покана за участие, образец на писмо за съгласие от родител или настойник.
- Проектиране и разработване на контролирани сравними езикови материали и езикови задачи, подходящи за оценка на уменията за четене и нивата на декодиране на информацията и разбиране на съдържанието при четене на ученици в началните класове за двата езика.Текстовете са създадени специално за предвидените изследователски цели на италиански език. Текстовете имат специфична структура: всеки от тях се състои от пет епизода, като нивото на трудност на текста нараства с всеки следващ епизод. След всеки епизод се задават по два въпроса към текста с четири варианта за отговор, от които може да се избере правилният.Текстовете са преведени на български. Преводът беше допълнително адаптиран, за да съответства на приетата сложност (дължина на изречение, изчислена като среден брой думи в изречение, и дължина на думата, изчислена като среден брой букви в дума), лексикални характеристики (процент уникални думи в текста спрямо избран за възрастта референтен списък; разпределение между „основна лексика“, думи с висока честота на употреба и думи с относително по-ниска честота, отнасящи се до ежедневни предмети или действия и морфо-синтактични характеристики (дълбочина на синтактичното дърво или най-дългия път от корена на дървото до листата (думите); средната дълбочина на синтактичното дърво на подчинените изречения; словореда на подчинените изречения; дължината на зависимите връзки и др.).
- Проектиране и разработване на контролирани сравними езикови материали и езикови задачи, подходящи за оценка на нивото на знание за основния речников запас и неговата подходяща употреба от учениците в началните класове за двата езика.Експериментите за проверка на разбирането на значението на подбрано множество от думи бяха проведени частично контролирано по време на Софийския фестивал на науката (11 – 14.05.2023 г.) и на Европейския ден на езиците (30.09.2023 г.) в София със 73 респонденти. Работата по създаване на задачите и провеждането на експериментите, както и анализът на получените резултати бяха представени пред италианския екип по време на работна среща в Пиза (6 ноември 2023 г.).
- Определяне на целевите групи и договаряне на събирането на данни с училищните власти и родителите.В Италия е проведен експеримент със 120 ученици от 2. до 5. клас включително. В България е осъществено сътрудничество с 21. средно училище „Христо Ботев“ в град София за провеждане на експеримента с 80 ученици от 2. до 5. клас. Данните за съгласие от родителите или настойниците са в процес на обработка.
През 2024 година бяха изпълнени следните дейности:
- Събиране на данни, илюстриращи уменията за четене на деца от целевите групи (2., 3., 4. и 5. клас) за двата езика.
В периода 19.02.2024 г. – 29.02.2024 г. бяха осъществени сесии за събиране на аудио- и тактилни анонимни данни от ученици (2., 3., 4. и 5. клас), илюстриращо уменията им за четене.
Участие в изследването взеха общо 72-ма ученици от 21. средно училище „Христо Ботев“, град София: 21 от втори клас, 18 от трети клас, 14 от четвърти клас, 18 от пети клас.
За втори клас беше предвидено четене на два епизода, за трети – три и т.н. Бяха проведени по две сесии с всеки ученик – при първата текстовете бяха прочетени на глас, а при втората – наум. При провеждане на проучването записът на всеки от участниците беше подробно документиран и придружен от кратка анонимна анкета за възраст, доминантна ръка, опит с употреба на електронни устройства и др. - Събиране на данни за деца от целевите групи за двата езика по отношение на техните лексикални познания чрез асоциативни и тематични езикови задачи.
В специално конструираните за експеримента текстове след всеки епизод се задават по два въпроса с четири варианта за отговор, от които може да се избере правилният. Основната цел е не да се провери разбирането на текста и възможностите за аналитично мислене, а да се провери при четенето наум дали учениците наистина четат, а не само проследяват думите в текста с пръст. Независимо от това, въпросите изискват лексикални познания, съобразени с възрастта, и в грешните отговори са заложени възможни подгрешни асоциации. По тази причина събраните отговори могат да бъдат използвани за съпоставително изследване, наред с резултатите от други експерименти, което оценява лексикалните познания на учениците.
Броят на въпросите, на които учениците отговориха, e съответно: за втори клас – 84; за трети клас – 108; за четвърти клас – 112, за пети клас – 180 въпроса. - Предварителен анализ на данните, илюстриращи уменията за четене и лексикалните знания (за всеки език и междуезиково).
Българските текстове бяха обработени с Българската многокомпонентна система за първична обработка и лингвистична анотация, в която са включени няколко инструмента за обработка на естествен език, включително автоматично разделяне на изречения и токъни, автоматично определяне на основната форма и граматичните характеристики, както и автоматичне анализа на универсалните синтактични зависимости.
Лексикалните характеристики в българските текстове са контролирани по два начина: а) чрез сравняване на лексиката, използвана във всеки текст, със списък, съдържащ думи от общата лексика на езика; и б) чрез изчисляване на съотношението между уникални леми (основни форми) и техните словоформи, т.е. съотношението между броя на лемите и броя на словоформите, които се срещат в текстовете.
Сравнението на дължината на думите и изреченията в български и италиански текстове показва, че в български се запазва сравнително малкият брой думи в изречението, както и тенденцията да се използват сравнително кратки думи със сравнително проста морфологична структура. Малко по-голямата средна дължина на думите в българските текстове се дължи на морфологичния строеж на съществителните, прилагателните и някои местоимения и числителни, които включват определителни членове. По същия начин относително по-малкият среден брой думи в българския език може да се обясни с това, че в италиански определителният и неопределителният член са самостоятелни думи.
Полученият набор от данни беше анализиран с програмата за статистическа обработка R с помощта на обобщени адитивни модели (GAMs), използвайки пакета gamm4, версия 0.2-6 (Wood, 2017).
За да се анализират факторите, влияещи върху скоростта на четене, се използва времето за проследяване на думата (токъна) с пръст като зависима променлива за двата модела GAM към независимите променливи: класа (от 2. до 5. клас) и типа на четене (на глас или наум) като категориални фактори и дължината на думата или честота на думата като числови фактори. За да се отчетат индивидуалните променливи в извадката и да се контролират ефектите от лексикалната вариативност в текстовете, индивидуалните участници и отделните токъни се използват като произволни ефекти.
Резултатите показват, че времето за проследяване с пръст е значително по-кратко при четене наум, отколкото при на четене на глас за 3., 4. и 5. клас (p-стойност < 0,001). В допълнение се наблюдава тенденция към намаляване на времето за проследяване с пръст при всеки по-горен клас (p-стойност < 2e − 16), с изравняване между 4. и 5. клас и при двата типа четене. Приемаме, че този ефект на изравняване се дължи на по-голямата сложност на следващите епизоди, прочетени от учениците от 5. клас.
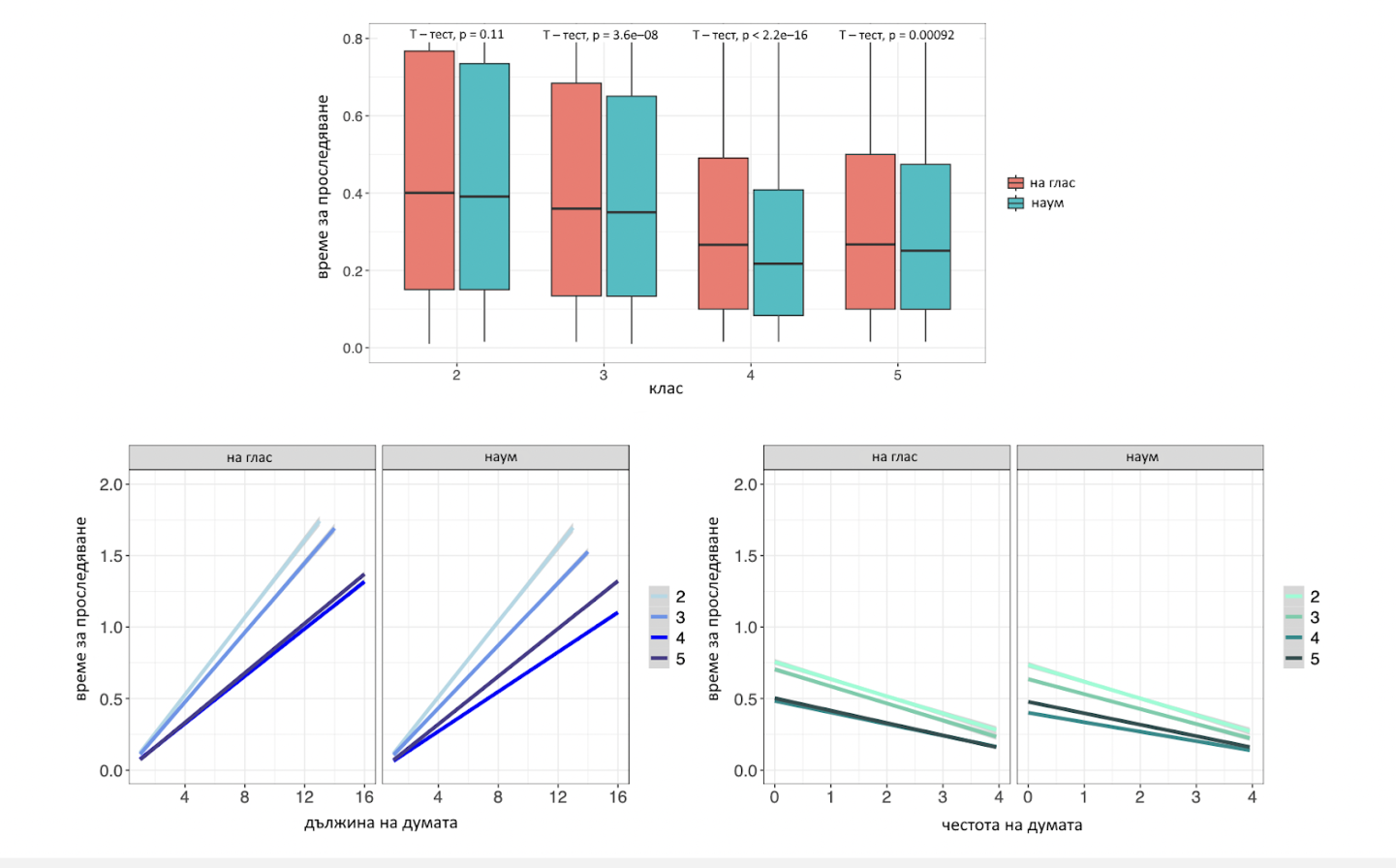
Фигура 1. Представяне на някои статистически резултати и техните корелации
Ефектът от дължината на думата (долния ляв панел на Фигура 1) и честотата на думите (долния десен панел на Фигура 1) върху времето за проследяване показва значително влияние на възрастта (2., 3., 4. или 5. клас), като скоростта на четенето при учениците в по-ранна възраст (2. и 3. клас) се влияе в по-голяма степен както от дължината на думите, така и от честотата на думите. Резултатите, наблюдавани и при италиански ученици (Marzi et al., 2020; Ferro et al., 2024), показват, че българските ученици от 4. и 5. владеят не само по-голям речников състав от учениците във 2. и 3. клас, но и по-дълги и по-рядко срещани думи. В резултат на това темпото на проследяване с пръст на българските ученици от 4. и 5. клас се забавя в по-малка степен при по-дълги думи (левия панел) и при по-редки думи (десния панел), отколкото темпото на българските ученици от 2. и 3. клас.
Резултатите също така показват значително взаимодействие между дължината на думите или честотата на думите и типа четене, като четенето на глас с проследяване на думите с пръст е повлияно в значителна степен както от дължината, така и от честотата на думите, отколкото четенето наум (p-стойности < 2e − 16). Тези доказателства не само показват, че по-дългите и по-редки думи са по-трудни при четене и съответно при ментална обработка. Освен това тяхната артикулация отнема повече време, за да бъде планирана и изпълнена. Това предоставя допълнително косвено доказателство за силната корелация между времето за проследяване с пръст и времето за артикулация при четене. - Подготовка, организиране и провеждане на 8-часов курс по тематиката на проекта за повишаване на квалификацията на педагогическите специалисти.
На 16 и 17 март 2024 г. беше организиран тематичен курс за повишаване на квалификацията на педагогическите специалисти и придобиване на квалификационни кредити съгласно Наредба №15/22.07.2019 г. на Министъра на образованието и науката (за учители по български език от начален и прогимназиален етап етап на обучение) „Оценка на уменията за четене и разбиране в начална училищна възраст“.
Лектори на тематичния курс бяха членовете на екипа от българска страна: проф. д-р Светла Коева, доц. д-р Цветана Димитрова, гл. ас. д-р Валентина Стефанова, гл. ас. д-р Христина Кукова, гл. ас. д-р Мария Тодорова и д-р Ивелина Стоянова.
Линк към курса
През 2025 година бяха изпълнени следните дейности:
Събиране на данни, илюстриращи уменията за четене на ученици от целевите групи (3., 4. и 5. клас) за двата езика.
- В периода 10.02.2025 г. – 14.02.2025 г. бяха осъществени сесии за събиране на аудио- и тактилни анонимни данни от ученици (3., 4. и 5. клас), илюстриращи уменията им за четене.
- Участие в изследването взеха общо 52-ма ученици от 21. средно училище „Христо Ботев“, град София: 20 от трети клас, 18 от четвърти клас, 14 от пети клас.
- За трети клас беше предвидено четене на три епизода, за четвърти клас – четири и за пети клас – пет. Бяха проведени по две сесии с всеки ученик – при първата текстовете бяха прочетени на глас, а при втората – наум. При провеждане на проучването записът на всеки от участниците беше подробно документиран и придружен от кратка анонимна анкета за възраст, пол, първи език, доминантна ръка, опит с употреба на електронни устройства и др.
Събиране на данни за целевите групи за двата езика по отношение на техните лексикални познания чрез асоциативни и тематични езикови задачи
- В специално конструираните за експеримента текстове след всеки епизод се задават по два въпроса с четири варианта за отговор, от които може да се избере правилният. Основната цел е не да се провери разбирането на текста и възможностите за аналитично мислене, а да се провери дали при режим четене наум учениците не четат механично, или само проследяват думите в текста с пръст. Независимо от това, въпросите изискват лексикални знания, съобразени с възрастта, и в грешните дистрактори са заложени възможни грешни асоциации. По тази причина събраните отговори могат да бъдат използвани за съпоставително изследване, наред с резултатите от други експерименти, които оценяват лексикалните знания на учениците.
- Броят на въпросите, на които учениците отговориха, e съответно: за втори клас – 84; за трети клас – 108; за четвърти клас – 112, за пети клас – 180 въпроса. И при четене на глас, и при четене наум доминира високата точност – над 50% от отговорите са напълно верни (questAccuracy = 1), което показва добро разбиране на текста и при двата типа четене.
- При четене на глас се наблюдават повече напълно верни отговори (56.4% срещу 50.8%), както и по-високи стойности на точност (0.9 – 12.9% срещу 9.1%). Делът на ниските стойности (0 – 0.6) е по-малък – 3.8% спрямо 8.9%. Следователно учениците разбират текста по-добре, когато четат на глас. При четене наум се увеличават междинните стойности – диапазонът 0.5 – 0.75 е по-висок (около 16%) в сравнение с четенето на глас (около 10%). Това показва, че при четене наум по-често се достига до частично разбиране на текста.
- Може да се направи заключение, че учениците разбират текста по-добре, когато четат на глас, тъй като по този начин се комбинират слуховото и речевото възприятие, което подпомага задържането на вниманието и разбирането на информацията. При четене наум разбирането се основава единствено на вътрешното внимание, което по-лесно може да бъде нарушено от външни фактори и да доведе до повече частично верни отговори.
Предварителен анализ на данните, илюстриращи уменията за четене и лексикалните знания (за всеки език и междуезиково).
- За да се изследват развойните промени в скоростта на четене, бяха наблюдавани времето за четене на глас и наум при български и италиански ученици.
- Всички статистически анализи и визуализация на данните са извършени с помощта на R (версия R-4.5.1, R Core Team, 2025). За нелинейни регресионни графики са приложени обобщени адитивни модели (Generalised Additive Models, GAMs). Допълнителният анализ на езиковоспецифичните данни за български е направен с помощта на структурирана Excel таблица, която автоматично предоставя възможности за филтриране и сортиране. Този формат улесни структурирането, анализа и визуализацията на данните. Данните бяха обобщени и анализирани поотделно за думи с 5, 6, 7 и 8 букви от и впоследствие обработени и обобщени в Excel чрез PivotTables и функции като AVERAGE.
- За надеждността на анализа от двете множества от данни бяха премахнати токъни с дълго време при четене – стойности над 3,75 секунди – съответстващи на крайната част на разпределението (0,2% от токъните) и отразяващи единични случаи на липса на активност. Така се намалява влиянието на аномалиите, без да се променя общият модел на данните. Токъни с регистрирано време за четене от 0 секунди също са изключени от анализа (3% от токъните при българските данни), тъй като те съответстват на думи, които не са били проследени чрез движение на пръста, а не реалното време за четене. Тази предварителна обработка намалява влиянието на нетипични стойности.
- За да се изследва по-подробно лексикалното влияние върху четивните умения на българските ученици, скоростта на проследяване на текста с пръст беше сравнена за пълнозначни думи (съществителни, глаголи, прилагателни, наречия), служебни думи (предлози, съюзи) и местоимения.
- Групите се различават съществено: пълнозначните думи изискват лексикален достъп и семантична интеграция, докато служебните думи обикновено са по-къси, по-чести и се обработват до голяма степен автоматично, без необходимост от фокусирано внимание.
- В малките класове разликата в скоростта на четене между пълнозначни и служебни думи е относително малка. С напредване на възрастта и повишаване на уменията за четене разликите в скоростта стават по-изразени, особено при четене наум.
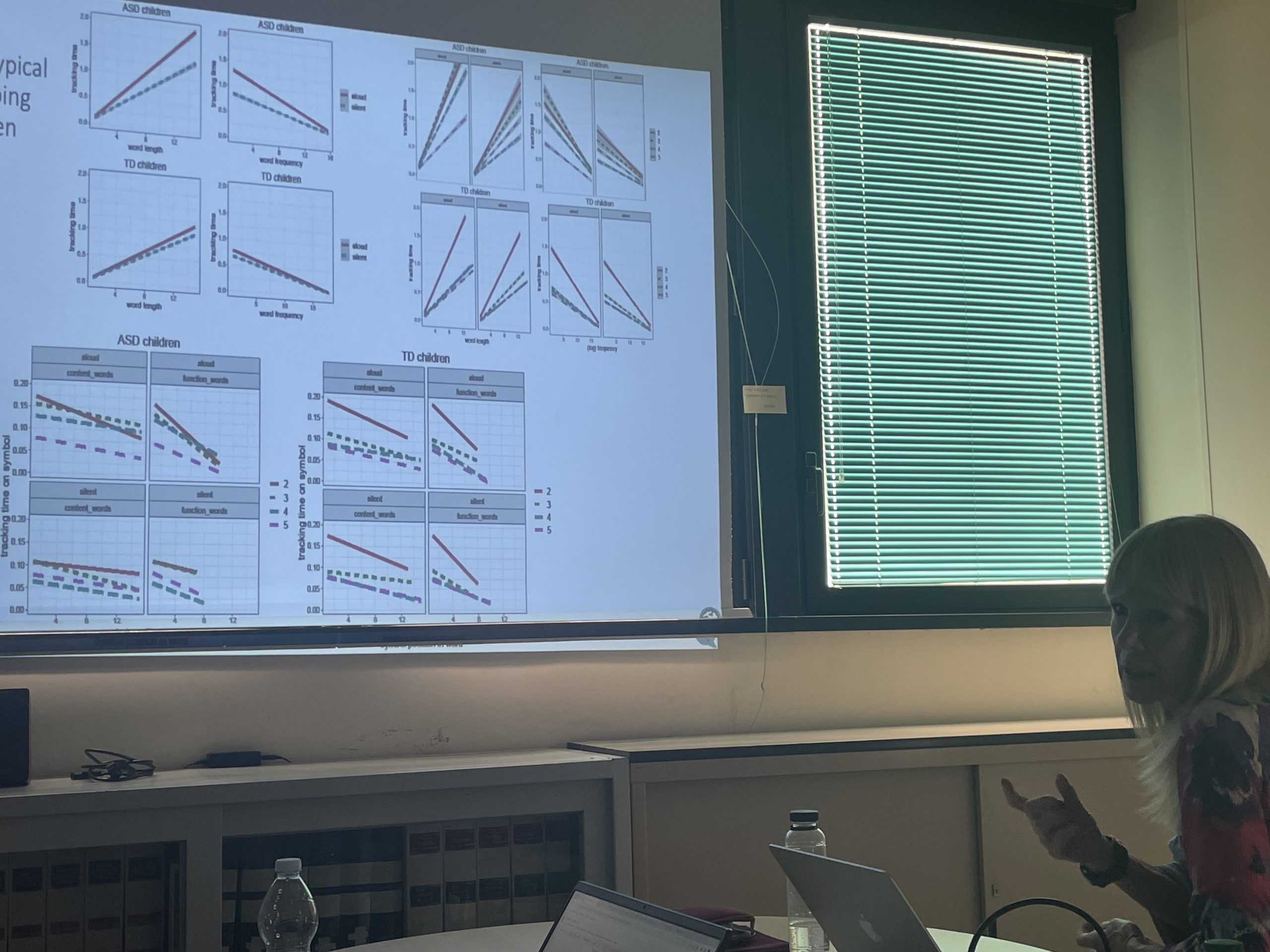
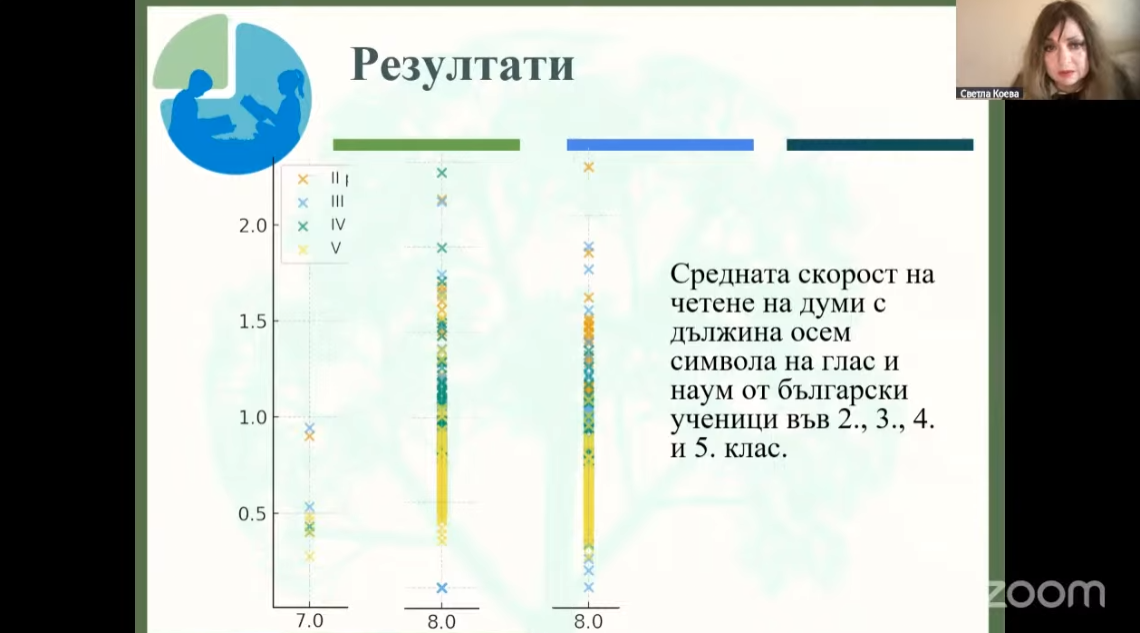
- Резултатите за скоростта на четене на различни части на речта – прилагателни (ADJ), наречия (ADV), съществителни (NOUN), числителни (NUM), глаголи (VERB) и местоимения (PRON) – за пример при думи с 6 букви на български (Фигура 1.) показват, че прилагателните се четат най-бързо наум, което предполага лексикално познаване и по-лесна морфологична обработка.
- При съществителни, глаголи и наречия (пълнозначни думи) разликата между четене на глас и четене наум е значително по-голяма, което показва повишени когнитивни изисквания при четене наум.
- Фигура 2 илюстрира, че скоростта на четене нараства с напредването на класа, което показва, че четивните умения стават по-плавни с възрастта и опита. Четенето наум е по-бързо от това на глас, особено в по-горните класове, което отразява засилената автоматизация на процесите на декодиране и лексикален достъп.
- При учениците от 2. клас разликата между двата начина на четене е по-малка, тъй като те все още разчитат в голяма степен на артикулацията. До 5. клас разликата става по-изразена, което подкрепя развойния модел, според който четенето наум постепенно изпреварва по скорост четенето на глас.
- Конкретни наблюдения върху данните за български.
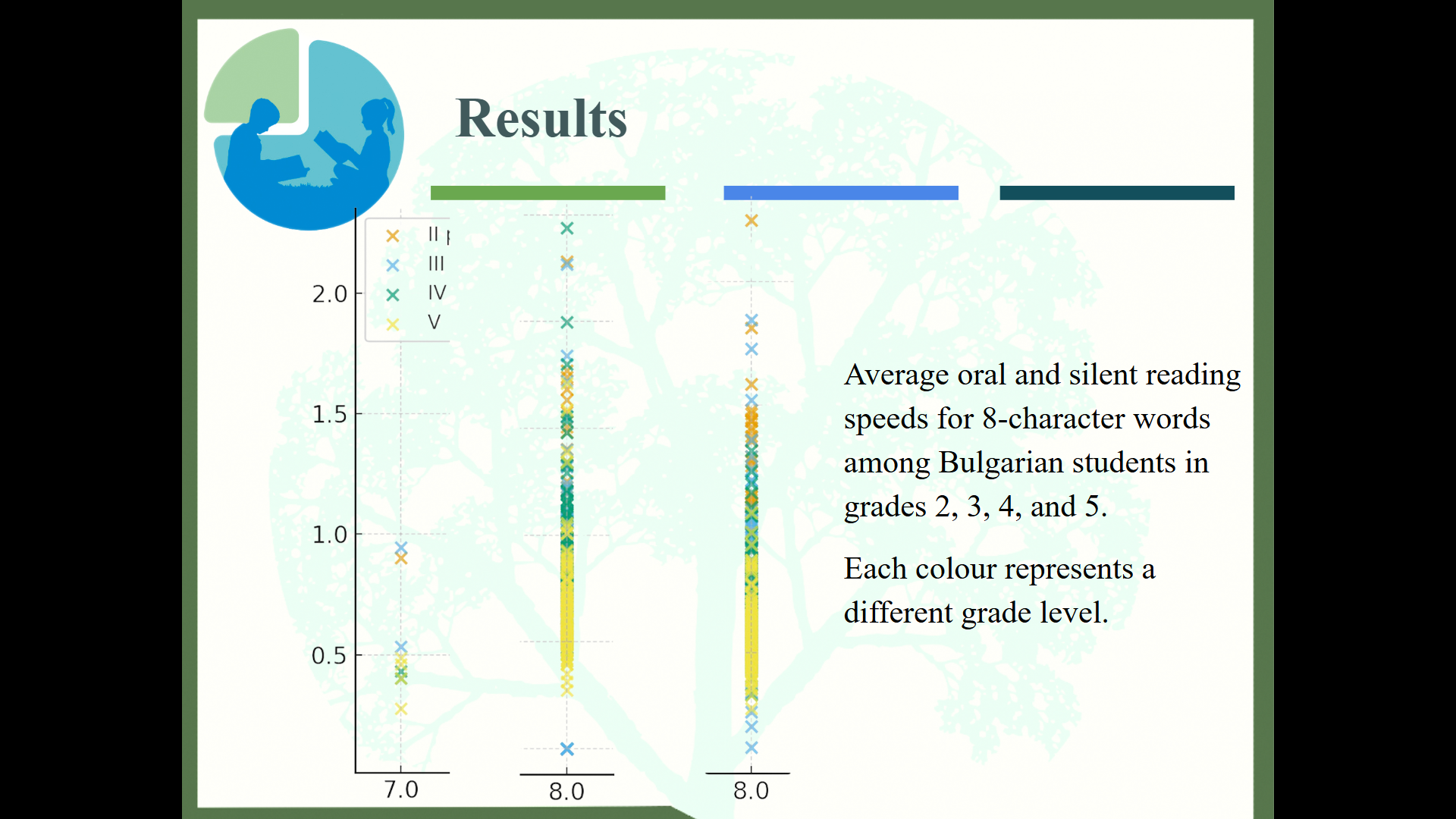
Препоръки за оптимизиране на практиките на преподаване при обучението по четене.
- Проведените анализи на събраните и обработени данни показват, че четенето на глас е силно препоръчително, особено в началния етап, тъй като по този начин се стимулира едновременното слуховото и зрителното възприятие и умението за фокусиране върху прочетеното. Следователно е необходимо да се засили тази практика в процеса на обучение, включително:
– да се практикува в часовете за нови знания и в часовете за упражнение;
– да се планират определен брой часове седмично за контролирано четене;
– да се насърчават учениците да четат на глас и вкъщи. - За да се избегне механичното четене, е препоръчително четенето на глас или наум да бъде съпроводено с дискусии и въпроси по съдържанието.
- Анализираните и обработени данни за времетраенето при четене показват моментни трудности при четенето и разбирането на избрана група от думи.
- Ако четенето наум има необичайна продължителност, препоръчваме да се използват различни стратегии за концентрация, които да подпомагат смисловата обработка при четенето наум, включително:
– подчертаване на ключови части на думите (представки/наставки/корен);
– водене на кратки бележки за значение, синоними и контекст;
– втбелязване на думи, които са били трудни за произнасяне, и думи с неясно значение, за да бъдат проверени. - Учениците трябва да бъдат стимулирани да се фокусират основно върху разбирането на текста, а не върху скоростта на четене.
- За да се обогатят лексикалните знания на учениците, е добре анализът на прочетеното да бъде подпомогнат чрез използване на речници за по-добро разбиране на думите: тълковен, синонимен. Добре е вниманието на учениците да бъде насочвано върху въпроса защо дадена дума е била трудна за тях.
Презентации
2023
По време на Осмия форум „Изследователски подходи в обучението по български език“, който се проведе на 1 ноември 2023 г. в зала „Акад. Александър Теодоров-Балан“ на Института за български език „Проф. Любомир Андрейчин“ в гр. София, беше представен проектът „Оценка на уменията за четене и разбиране в начална училищна възраст в България и Италия“ пред учени, университетски преподаватели, учители и експерти по български език. Докладът е изпратен за анонимно рецензиране в сп. „Български език“.
 |
 |
 |
По време на Международната научна конференция „Българистични езиковедски четения“, която се проведе на 23 и 24 ноември 2023 г. в Софийския университет „Св. Климент Охридски“, екипът на проекта от българска страна запозна участниците в конференцията с целите и задачите на проекта, както и с бъдещите експерименти, свързани с четивните умения на деца от целевата група на проекта. Докладът се очаква да бъде публикуван през следващата година в сборник от конференцията.
 |
 |
 |
На 6 декември 2023 г. в зала „Иван Евстратиев Гешов“ (207) на Българската академия на науките проф. Вито Пирели изнесе лекция на тема: Assessing reading literacy with the finger-voice span. Лекцията протече при засилен интерес от страна на научната общност; присъстваха представители на Българската академия на науките, университетски преподаватели, студенти и учители, както и експерти от Министерството на образованието и науката.
 |
 |
 |
2024
По време на Шестата международна конференция „Компютърна лингвистика в България“ проф. Вито Пирели (Институт за компютърна лингвистика „А. Замполи“, Италия) изнесе пленарен доклад на тема „Written Text Processing and the Adaptive Reading Hypothesis“. 10.09.2024 г. ![]()
По време на Шестата международна конференция „Компютърна лингвистика в България“ изсл. Андреа Надалини представи съвместна разработка на тема „Assessing Reading Literacy of Bulgarian Pupils with Finger–tracking“ с авторски колектив: Алесандро Лето, Андреа Надалини, Марчело Феро, Клаудия Марци, Вито Пирели, Цветана Димитрова, Христина Кукова, Валентина Стефанова, Мария Тодорова, Светла Коева. 10.09.2024 г. ![]()

По време на Втората международна научно-приложна конференция „Контакт на езици и култури. Съвременни ресурси в обучението по български език като чужд/втори“, която се проведе на 17-19 септември 2024 г. в гр. Велико Търново, проф. Светла Коева (Институт за български език „Проф. Любомир Андрейчин“ при БАН) представи доклад на тема „Приложение на езиковите технологии за оценка на усвояването на езика“.

На 1 ноември 2024 г. Христина Кукова (Институт за български език „Проф. Любомир Андрейчин“ при БАН) и Гергана Будинова (21. средно училище „Христо Ботев“, София) представиха разработка на тема „Изследване на уменията за четене – среща между наука и образование“ в рамките на Деветия форум „Изследователски подходи в обучението по български език“, гр. София. ![]()
 |
 |
 |
Мария Тодорова (Институт за български език „Проф. Любомир Андрейчин“ при БАН) беше гост-лектор в серията от уебинари на тема “I teach with technology”, организиран от Британската асоциация по приложна лингвистика BAAL Language Learning and Teaching SIG на 13.11. 2024 г. с тема “Theoretical Analyses and Natural Language Processing for and via Language Learning and Teaching”.

2025
По време на Третата международна конференция „Контакт на езици и култури 2025, Стандартизация – адаптация – практики в обучението по български език като чужд/втори“, която се проведе на 29-31 октомври 2025 в гр. Панагюрище, проф. Светла Коева (Институт за български език „Проф. Любомир Андрейчин“ при БАН) представи доклад на тема „Comparative assessment of Bulgarian students reading skills with finger tracking“, с авторски колектив: Svetla Koeva, Alessandro Lento, Andrea Nadalini, Marcello Ferro, Claudia Marzi, Vito Pirrelli, Tsvetana Dimitrova, Hristina Kukova, Valentina Stefanova, Maria Todorova, Ivelina Stoyanova.
 |
 |
 |
Публикации
2023
Светла Коева, Валентина Стефанова, Ивелина Стоянова, Мария Тодорова. Оценка на уменията за четене в начална училищна възраст. сп. Български език, 70 (2023), 4, 92–102. ISSN: 0005-4283, Online ISSN: 2603-3372. DOI: https://doi.org/10.47810/BL.70.23.04.08 (PDF)
2024
Alessandro Lento, Andrea Nadalini, Marcello Ferro, Claudia Marzi, Vito Pirrelli, Tsvetana Dimitrova, Hristina Kukova, Valentina Stefanova, Maria Todorova, and Svetla Koeva. 2024. Assessing Reading Literacy of Bulgarian Pupils with Finger–tracking. In Proceedings of the Sixth International Conference on Computational Linguistics in Bulgaria (CLIB 2024), pages 140–149, Sofia, Bulgaria. Department of Computational Linguistics, Institute for Bulgarian Language, Bulgarian Academy of Sciences. ISSN: 2367-5675. DOI: https://doi.org/10.47810/CLIB.24.14 (ACL, Scopus)
Vito Pirrelli, Svetla Koeva. Developing Materials for Assessing Reading Literacy and Comprehension of еarly Graders in Bulgaria and Italy. – Чуждоезиково обучение, 2024, кн. 1. ISSN: 0205–1834 (Print), 1314–8508 (Online). DOI: https://doi.org/10.53656/for2024-01-03 (PDF)
Светла Коева, Христина Кукова, Цветана Димитрова, Валентина Стефанова. Оценка на уменията за четене и разбиране в начална училищна възраст. Сборник от Втората международна научна конференция „Българистични езиковедски четения“, посветена на 100-годишнината от рождението на проф. Мирослав Янакиев, 23 – 24 ноември 2023 г., Софийски университет „Св. Климент Охридски“. ISBN 978-619-7785-06-7 (твърда подвързия), ISBN 978-619-7785-07-4. DOI: https://doi.org/10.5281/zenodo.17877190 (PDF)
Христина Кукова, Гергана Будинова. 2024. Изследване на уменията за четене – среща между наука и образование. Професионално образование, год. 26, кн. 4, с. 226 – 235. DOI: https://doi.org/10.53656/voc24-4-03
2025
Светла Коева. 2025. Приложение на езиковите технологии за оценка на усвояването на езика. В Сборник с доклади от Втората международна научно-приложна конференцията „Контакт на езици и култури. Съвременни ресурси в обучението по български език като чужд/втори“, 17-19 септември 2024. Университетско издателство „Св. Климент Охридски“, 2025, с. 89 – 100. ISBN 978-954-07-6258-6, ISBN 978-619-7785-20-3. DOI: https://doi.org/10.5281/zenodo.17876807
Claudia Marzi, Marcello Ferro, Andrea Nadalini, Vito Pirrelli, Maria Todorova, Tsvetana Dimitrova, Valentina Stefanova, Hristina Kukova, Svetla Koeva. Comparable reading development in Bulgarian and Italian: cross-linguistic insights from a finger-tracking study. Languages. (подаден за рецензиране)


Българския WordNet

Многоезиков корпус с изображения

Българският национален корпус

Речник на българския език, онлайн реализация на СКЛ

МЕТА СПОДЕЛЯНЕ – достъп до разнообразни езикови ресурси и технологии
Система за анализ на бизнес информация в интернет, езикови ресурси, разработени от СКЛ
