The First Bulgarian dissemination event in the context of the European Language Grid (ELG) will take place on 11th February 2022. The event consists of two workshops:
|
Workshop 1: European Language Grid Workshop When: February 11, 2022, from 10:00 a.m. to 11:30 а.m. (ЕЕТ) Where: Online, Zoom & YouTube The workshop will be in English, with simultaneous subtitling in Bulgarian. |
 Workshop 2: Multilingual Image Corpus Workshop When: February 11, 2022, from 12:00 p.m. to 1:00 p.m. (ЕЕТ) Where: Online, Zoom & YouTube The workshop will be in Bulgarian. |
| Automatic simultaneous subtitling of English presentations and translation into Bulgarian will be provided by ELITR and can be accessed at the following link. |
| The event will be streamed live on the YouTube channel of the Department for Computational Linguistics. |
Participants registered to take part in Zoom will receive connection details by 10 February 2022.
Workshop 1: European Language Grid Workshop
Do you use language technologies or language resources in creating products and services provided by your company, or as part of your research work? Do you work in the field of artificial intelligence, information and language technologies, robotics or natural language processing? Have you been looking for language applications to integrate into your products and services? Do you know enough about the platforms that provide these language applications? Do you have business strategies on how sharing products and services can contribute to the development of your company or research?
If the answer to at least one of the above questions is “yes” and you would like to learn more, you are welcome to attend our European Language Grid Workshop.
When: February 11, 2022, from 10:00 a.m. to 11:30 а.m.
Where: Online, Zoom & YouTube
European Language Grid is the fastest-growing platform for the sharing and dissemination of language resources, language processing tools and language technology services. In just a few months, the language resources and technologies shared on the platform have grown to 500.
Programme
This workshop will touch upon various topics, including:
- Overview of the European Language Grid platform
- Demo of the European Language Grid cloud platform
- Technological Multilingualism in Europe: current state of play
- Mini tutorial: how to integrate datasets into the European Language Grid platform
- Best practices from industry and potential users of European Language Grid
- Discussion with various stakeholders
10:00 – 10:05 Svetla Koeva (Institute for Bulgarian Language) Welcome and introduction ![]()
10:05 – 10:50 Katrin Marheinecke, Georg Rehm (DFKI) Overview presentation on the European Language Grid: covering ELG, ELE and an ELG demo ![]()
10:50 – 11:05 Penny Labropoulou (ILSP/RC Athena) Metadata in the European Language Grid and inclusion of data resources ![]()
11:05 – 11:10 Q&A ![]()
11:10 – 11:20 Lachezar Dzhakov (Skycode) Neural networks in a market-ready Bulgarian text-to-speech ![]()
11:20 – 11:30 Yolina Petrova (Identrics) The importance of the European Language Grid for media intelligence industry ![]()
In our globalized world language barriers affect cross-lingual communication and the free flow of knowledge and information. Language technologies, especially multilingual technologies, can help overcome these omnipresent and ubiquitous language barriers, significantly improving trade, administration, politics, communication and cross-cultural understanding.
The European Language Grid develops and deploys a scalable cloud platform, providing, in an easy-to-integrate way, access to hundreds of commercial and non-commercial language technologies for all European languages, including running tools and services as well as datasets and resources.
Workshop 2: Multilingual Image Corpus Workshop
Do you use multilingual and multimodal (text, audio and images) technologies or resources in creating products and services that your company provides, or in your research? Do you work in the field of artificial intelligence, robotics or computer vision? Have you been looking for multimodal and multilingual applications to integrate into your applications?
If your answer to at least one of the above questions is “yes” and you want to learn more, you are welcome to attend our Multilingual Image Corpus Workshop.
When: February 11, 2022, from 12:00 a.m. to 13:00 а.m.
Where: Online, Zoom & YouTube
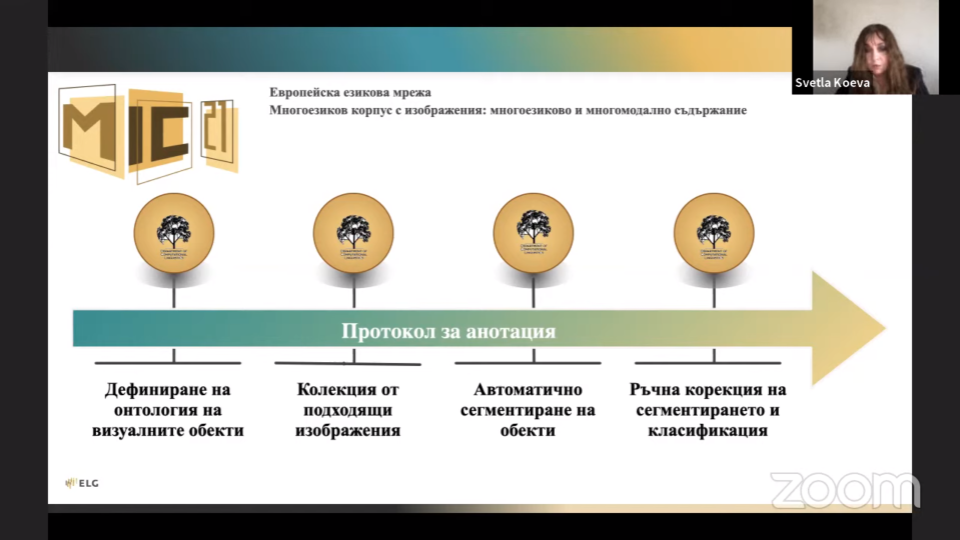
The shift from traditional data processing methods to new ones challenged by the necessity for processing big multimodal data has motivated the creation of a new image corpus, the Multilingual Image Corpus (MIC 21), a large collection of carefully selected images from thematically related domains supplied with precise object annotation for the purposes of segmentation and classification of objects in images.
The Multilingual Image Corpus will be available for download at the European Language Grid platform at the end of February 2022.
Programme
This workshop will touch upon various topics, including:
- Overview of the Multilingual Image Corpus
- Introduction to the Ontology of Visual Objects
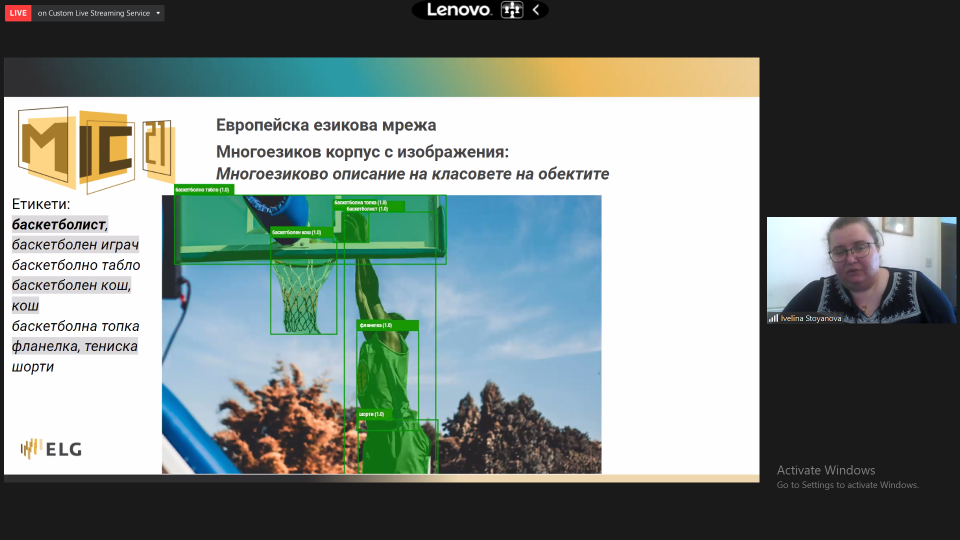
- Presentation of the multilingual descriptions of object classes in 24 languages
- Demo of object detection and classification
- Discussion with various stakeholders
12:00 – 12:25 Svetla Koeva (Department of Computational Linguistics, Institute for Bulgarian Language) Multilingual Image Corpus: a Multilingual and Multimodal Dataset ![]()
12:25 – 12:40 Ivelina Stoyanova (Department of Computational Linguistics, Institute for Bulgarian Language) Multilingua Descriptions of Object Classes ![]()
12:40 – 12:55 Yordan Kralev (Technical University, Sofia; Department of Computational Linguistics, Institute for Bulgarian Language) Multilingual Dataset Applications and Services ![]()
12:55 – 13:00 Q&A
The Multilingual Image Corpus (MIC21): (a) is a large dataset containing thousands of images and annotations; b) is designed according to an Ontology of Visual Objects; c) provides multilingual descriptions of objects in the images in 24 languages. The Multilingual Image Corpus aims at facilitating research and development in multilingual and multimodal data processing.
This dissemination event is organized within the EU-funded project European Language Grid (2019-2022).
This dissemination event is organized in cooperation with the European Language Grid National Competence Center in Bulgaria (the Institute for Bulgarian Language at the Bulgarian Academy of Sciences).
The event is organized by the Department of Computational Linguistics at the Institute for Bulgarian Language.